Turn pages into structured data instantly, like magic
End the pain of parsing. Let AI understand the page and extract the data for you.
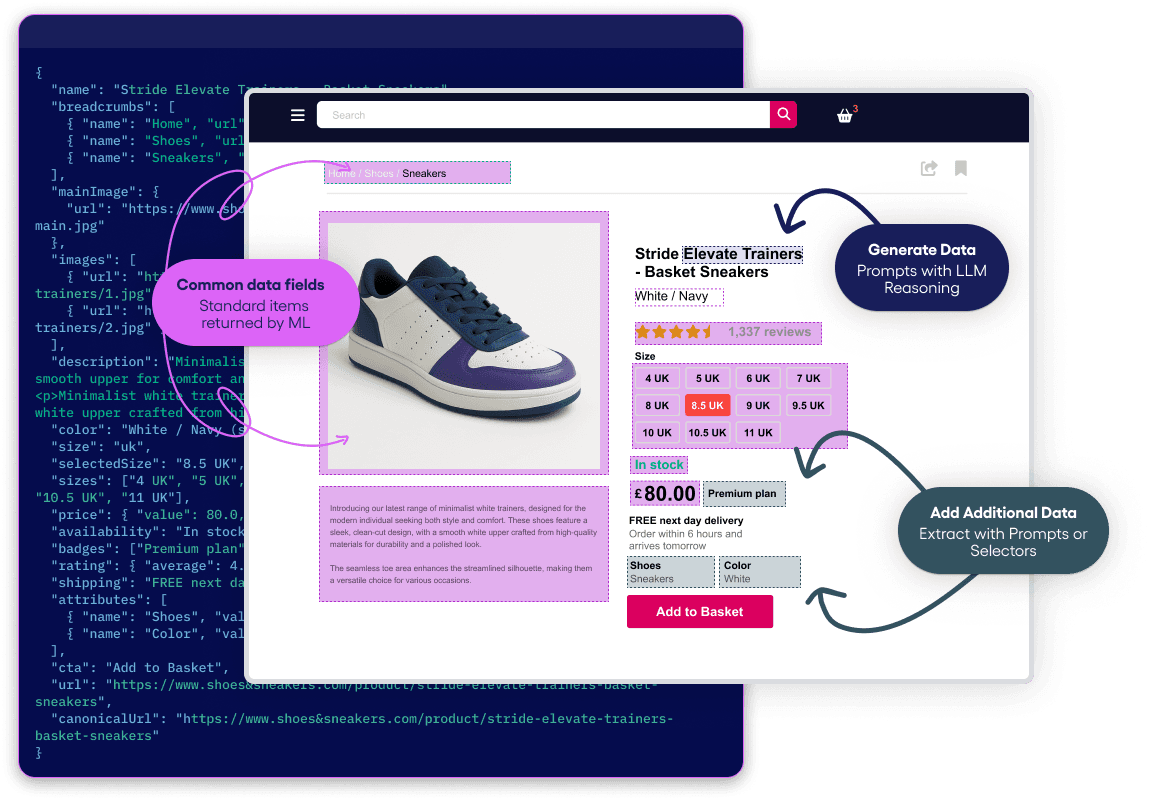
The hidden cost of writing parsers
Death by DOM
Identifying and testing XPath or CSS selectors is slow and repetitive.
Error-prone
"Awards, five-star reviews and millions of happy customers"
The results are in: Zyte customers love our products. Check out these views and reviews on independent sites.