From screenshot to shopping list in 90 seconds
Neha Setia Nagpal
10 min read ·
From screenshot to shopping list in 90 seconds
I built a mood board pipeline that starts with a screenshot. Claude Skills and Zyte API for search, product extraction, and image embedding at any scale.
I like to follow fashion. I also happen to be a developer advocate at Zyte, a large scale web data scraping company. These two things don't overlap as often as you'd think, but this week they did.
Here's what happened: I was scrolling through my feed and came across a stunning blush pink strapless gown with cascading fringe detail. The kind of dress you screenshot immediately and send to your best friend with no context, and wish for a magical link to buy similar dresses in your inbox.
I tried doing this manually. The process looked like this:
- Screenshot an outfit.
- Run it through a reverse image search.
- Open eight tabs and lose half of them in different tabs.
- Half the results are "get the look" articles with no buy links.
- The other half are sold out, don't ship to your country, you give up, and go back to scrolling.
Thirty minutes later you're comparing nothing against nothing.
So you do what any developer would: write a script. And it works. Once. Then you want a different dress and you're back in the terminal, hand-editing query strings, wondering why one retailer returned empty HTML. Fashion e-commerce sites are some of the hardest pages to scrape on the open web: JavaScript-rendered product galleries, aggressive bot detection, rotating proxies that still get fingerprinted, and brand-protection layers that serve you a CAPTCHA wall instead of a product page. Your script works on site A, breaks on site B, and site C has changed its DOM. The code ran. You didn't get anywhere.
What I actually wanted was to drop a screenshot and get a mood board. No tabs. No terminal. No debugging. Just the answer.
What a fun use case for LLMs.
So I built a Claude Skill that does exactly that.
What I built
Three Claude Skills chained together. You drop a screenshot into Claude and get back an HTML mood board with real product images, prices, and buy links. No tabs. No manual searching. No scripts to maintain.
| Skill | What it does |
|---|---|
| serp-search | Searches search engine via Zyte API, returns structured results |
| product-extractor | Extracts structured product data (price, image, brand) from any product URL via Zyte API |
| mood-board | Orchestrator: chains the two skills above, filters results, fetches images, generates HTML |
Two of the three skills are Zyte API-specific. The third is the glue.
What surprised me
I dropped this screenshot into Claude:

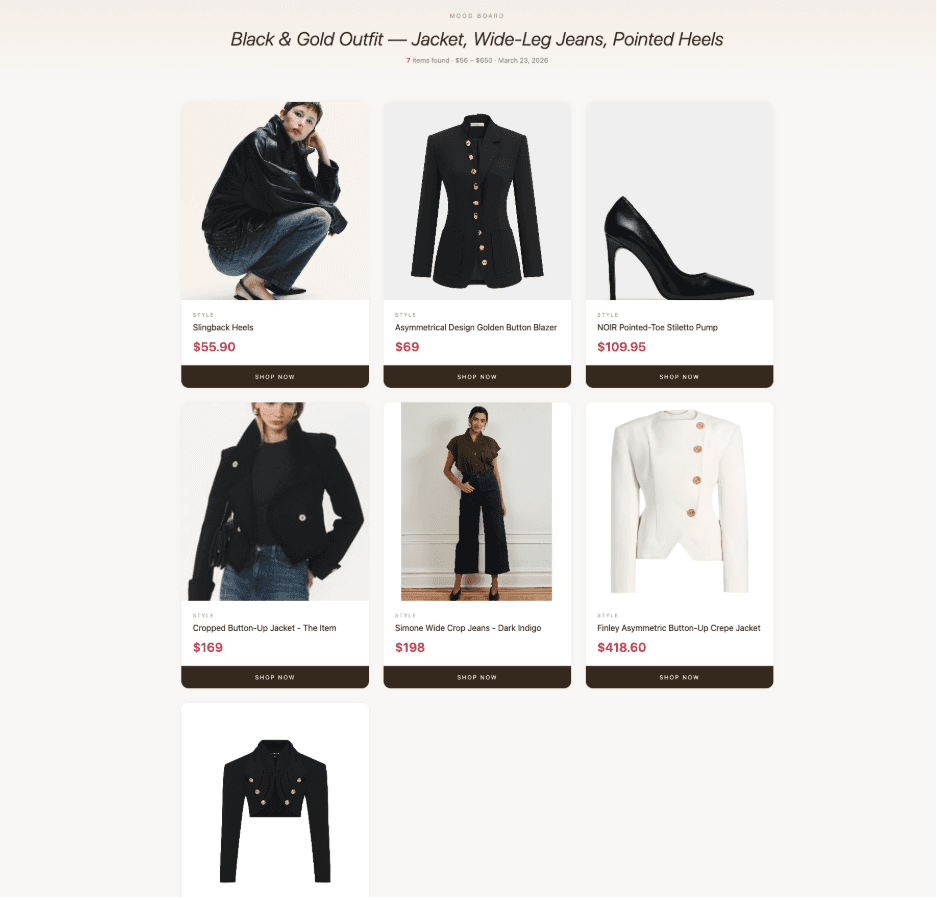
It's a full outfit: a black asymmetric jacket with gold buttons, dark indigo wide-leg cropped jeans, and black pointed-toe heels. Three distinct pieces.
I said: "Find similar pieces to this image."
The first thing Claude did was ask me a question.
The outfit has a few distinct pieces. What would you like me to find similar items for? The full outfit (jacket, jeans, and heels), just the black asymmetric jacket with gold buttons, just the dark wide-leg cropped jeans, or just the black pointed heels?
That caught me off guard. I expected it to pick one item and run with it. Instead, it looked at the image, identified three separate products, and asked me to scope the search before burning any API calls. I picked the full outfit.
Then the pipeline kicked in.
What happened under the hood
Search engine results page (SERP) search. The skill broke each piece into a tight four-to-five word query and ran two variations per item through Zyte API's SERP extraction. "Black asymmetric gold button jacket buy online." "Black cropped jacket gold buttons women shop." Six searches total. The trick is keeping queries short. Long, descriptive queries return category pages and editorial roundups. Short, specific queries return actual product listings.
URL filtering. The search returned about 60 results across all three items. Most of those were collection pages, browse pages, filtered search results. The skill stripped anything with /collections/, /browse/, /s?k=, or filterBy in the URL. Fourteen individual product pages survived.
Product extraction. Each surviving URL went to Zyte API's product extraction endpoint. This is where the JavaScript rendering, bot detection, and anti-scraping layers get handled. I didn't write a single parser. No CSS selectors. No XPath. Zyte's AI extraction returned structured JSON: product name, price, currency, brand, color, images, and variants. Out of eight URLs I sent, all eight came back clean. Confidence scores above 0.99.
The image problem. This is the part I didn't see coming. The extraction worked perfectly. Every product had a valid image URL. But when the mood board rendered, every card was blank. No images.
The image URLs pointed to retailer content delivery networks (CDNs) that block cross-origin requests. The HTML was fine. The URLs were fine. The CDNs just refused to serve the images to an unfamiliar origin.
The fix: route image downloads through Zyte API too. The same infrastructure that handles bot detection for product pages also handles it for images. Download each image, base64-encode it, embed it directly in the HTML. The mood board file went from 5KB to 750KB, but now it renders anywhere: offline, in email, in a Notion embed, on a phone. Zero broken images.
Generation. The final step assembled everything into a styled, responsive HTML page. Product cards sorted by price, hover animations, and "Shop Now" links back to each retailer.
The result
Seven products across three categories, from $56 to $650. Four jackets (including one that's nearly identical to the one in the screenshot, at $169). One pair of dark indigo wide-leg cropped jeans. Two pairs of black pointed-toe heels. All with images, all with real prices, all with working buy links.
The whole thing took under two minutes. No tabs. No lost URLs. No debugging blocked requests.
Three things that stood out
One query isn't enough. "Black asymmetric gold button jacket" returned a mix of product pages and category pages. A second, slightly different query ("black cropped jacket gold buttons women shop") filled the gaps. The skill now runs two query variations per item and merges results. Broad queries return editorial roundups. Tight, varied queries return things you can actually buy.
The AI description is the linchpin. The quality of the mood board depends entirely on how well Claude describes the image. "Black jacket" gives you garbage. "Black asymmetric gold button jacket" gives you exactly what you want. Prompt engineering for the description step matters more than any other part of the pipeline.
Fashion sites fight back. Sites that sell the dresses you'd actually want to buy are the same sites that actively fight automated access. JavaScript-heavy single-page applications (SPAs) that serve empty HTML to anything that isn't a full browser. Session-based dynamic pricing. Anti-bot fingerprinting that blocks anything that looks automated. I didn't have to think about any of it. Zyte API's browser rendering and anti-ban management handled it behind a single POST request. But I noticed: sites that would return empty responses to a regular requests.get() came back with clean, structured data through Zyte.
The architecture, briefly
1Screenshot
2 ↓
3Claude describes the image → 4-5 word search query per item
4 ↓
5serp_search.py → Zyte API SERP extraction → 60 raw URLs
6 ↓
7URL filter → strips category/browse pages → 14 product URLs
8 ↓
9fetch_price.py → Zyte API product extraction → structured JSON
10 ↓
11fetch_images.py → Zyte API image download → base64 data URIs
12 ↓
13generate_moodboard.py → self-contained HTML mood boardEach step is a separate script. The mood-board SKILL.md tells Claude how to chain them. Claude reads the orchestration instructions, decides which scripts to call and in what order, and handles the data flow between them. You don't see any of this. You see a conversation.
What Zyte API handles (so I don't have to)
This is the part that matters if you've ever tried to build a product scraping pipeline yourself.
SERP extraction. I didn't set up a custom API key, manage quotas, or parse raw HTML from a search results page. Zyte API returns structured organic results: URL, title, description, and rank. One API call per query.
Product extraction. No CSS selectors. No site-specific parsers. No maintaining a different scraping config for each retailer. Zyte's AI extraction understands product pages across thousands of e-commerce sites. It returns the same structured schema whether the page is server-rendered HTML, a React SPA, or a JavaScript-heavy product gallery that doesn't load until the third scroll event.
Image fetching. The same infrastructure handles downloading images from CDNs that block direct requests. The same anti-bot handling. One more API call per image.
Ban management. I didn't think about it once. No rotating proxies, no browser fingerprinting, no CAPTCHA solving. Zyte handles this at the infrastructure layer. Every request I sent came back clean.
Where this goes next
The mood board is a fun demo. The architecture is the point.
This skill and a production fashion price monitoring system use the same pipeline. The difference is scale and what you do with the output.
Discovery. This skill starts with an image and finds similar products. A price monitoring system starts with a product catalog and finds where those products are listed across the web. Both use SERP search to identify target URLs. At scale, this becomes a recurring crawl: discover new listings, track existing ones, and flag delisted products.
Extraction. This skill extracts one product per page. A monitoring system extracts the same fields from hundreds of thousands of pages. The Zyte API call is identical. What it does interactively, a production system does on a scheduled spider, with Zyte API handling the anti-ban layer underneath.
Comparison. This skill puts everything in a mood board for visual comparison. A monitoring system puts everything in a database for price change detection, minimum advertised price (MAP) violation alerts, and automated reporting.
Infrastructure. This is the part that doesn't change. Whether you're extracting one dress or a million products, the anti-ban challenge is the same. Zyte API handles browser rendering, proxy rotation, and ban management at both scales. The skill user and the enterprise customer are calling the same endpoint.
The composable skill pattern scales the same way. The serp-search skill becomes a discovery spider. The product-extractor skill becomes an extraction pipeline. The mood-board orchestrator becomes a scheduling and alerting system. Each component is independently testable, independently deployable, and independently scalable.
The difference between my Saturday afternoon project and a production deployment is scheduling, frequency, and what you do with the output. The data pipeline underneath is the same.
Try it yourself
The mood board skill is open source at github.com/NehaSetia-DA/mood-board-skill. You'll need a Zyte API key (there's a free tier) and Claude with skills enabled.
Drop an image of any product into the conversation. Doesn't have to be fashion. Sneakers, furniture, electronics, skincare. The skill doesn't care what kind of product it is. Zyte API's extraction works across categories.
If you build something with it or adapt it for a different use case, I'd love to see it. Find me in the Extract Data community on Discord.
And if you're working in fashion e-commerce and the scale problem resonates: Zyte's data delivery team handles exactly this. Production-grade product extraction from the sites that fight back hardest.
More learn articles
Keep learning
 Use case
Use caseWhat is a residential proxy?
Learn what residential proxies are, how they compare to datacenter proxies, and why modern web scraping needs more than IP diversity.
10 min read
 Use case
Use caseHow much do rotating proxies cost?
Learn how much rotating proxies cost, what affects pricing, and why total web scraping costs often go beyond proxy subscriptions.
10 min read
Use caseHow do rotating proxies work?
Learn how rotating proxies work, when to use them for web scraping, and why IP rotation alone is not enough for reliable data access.
10 min read




_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
