Get web data delivered quickly and accurately.
We extract data for the largest companies in the world so they don't have to. Tell us about your project, we'll handle the rest.
Our data delivery team is standing by to get you the data you need.
Standardized Data
Plug and play data service: We will find, extract, clean and format some of the largest datasets so you don't have to.
Customized Data
Anything you need: If standard datasets don't cut it, Zyte extends and customizes existing datasets or collects unique data for your specific use cases.
Legal Guidance
Compliance peace of mind: When you work with Zyte, you work with our world-class legal team, globally recognized as an authority on ethical scraping practices.
Data feeds for your business
99.99% data accuracy rate to drive your business forward
Leverage our world-class legal team to inform compliance
Data when you need it
Complete web scraping service for any business
Standard and bespoke web data extraction projects
Trusted by data-driven organizations



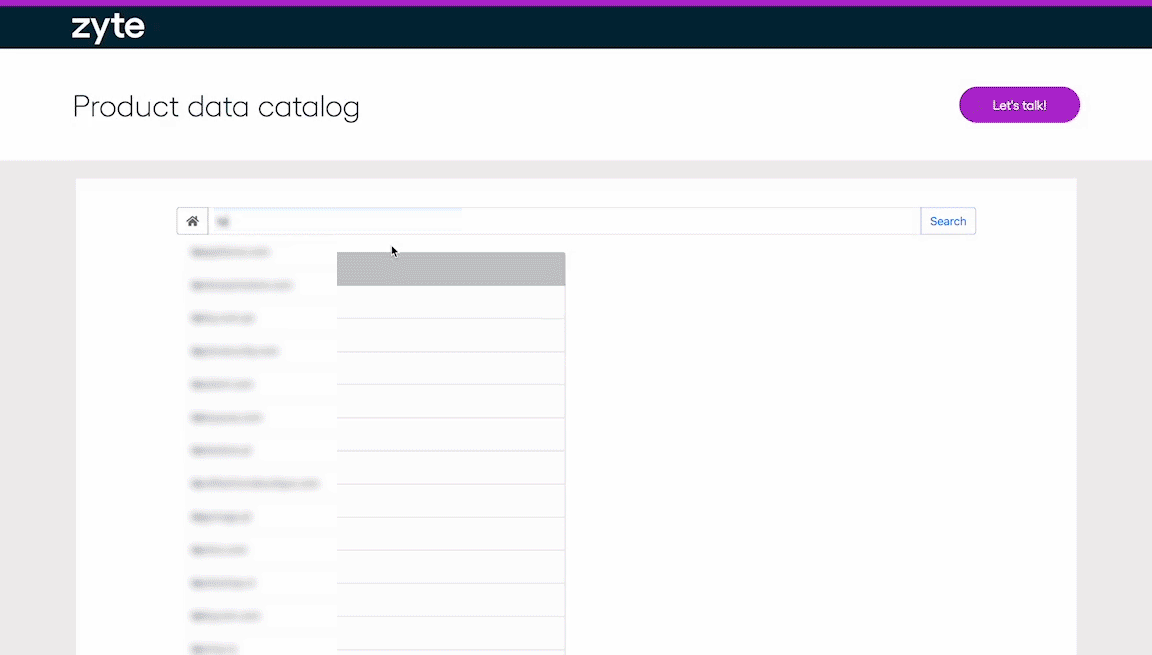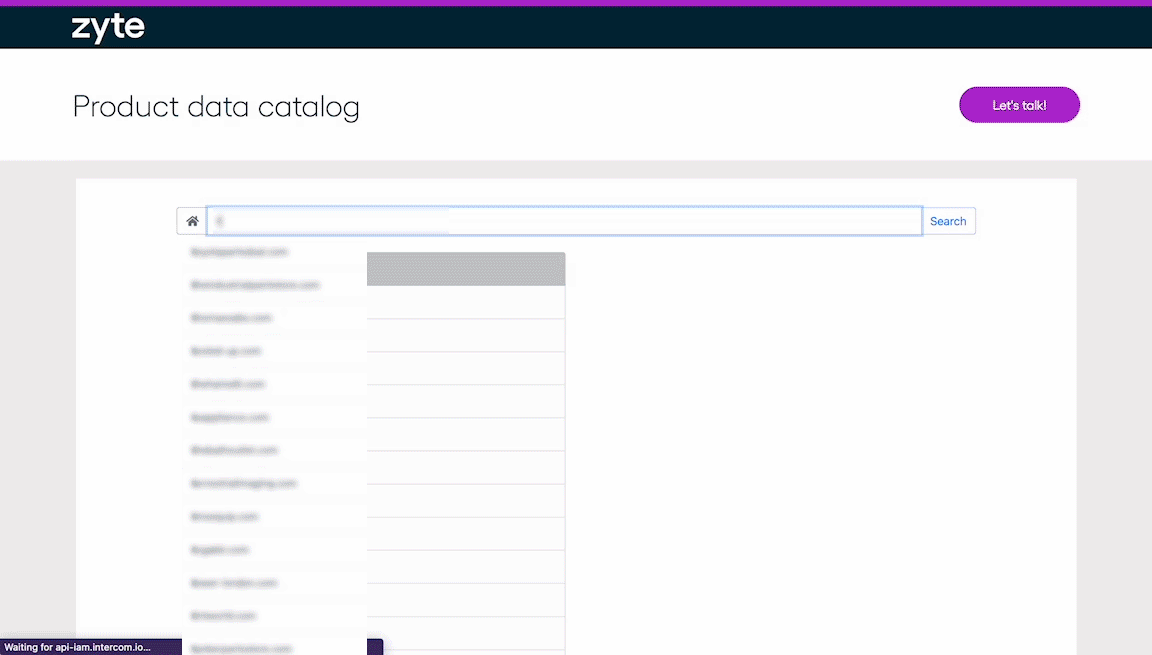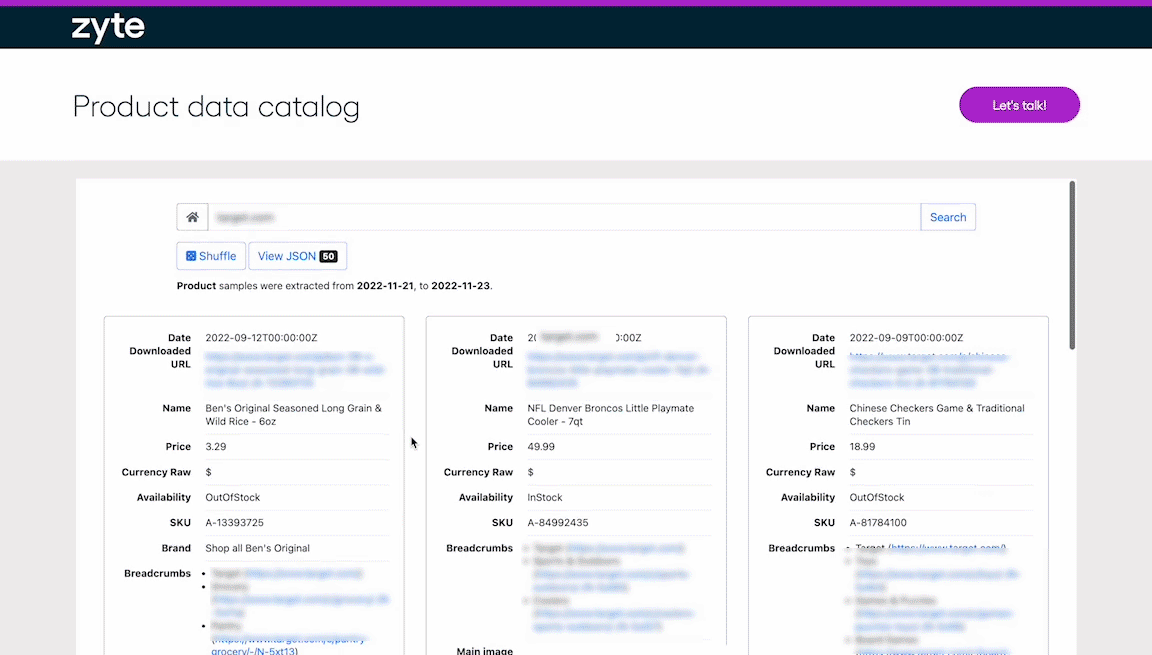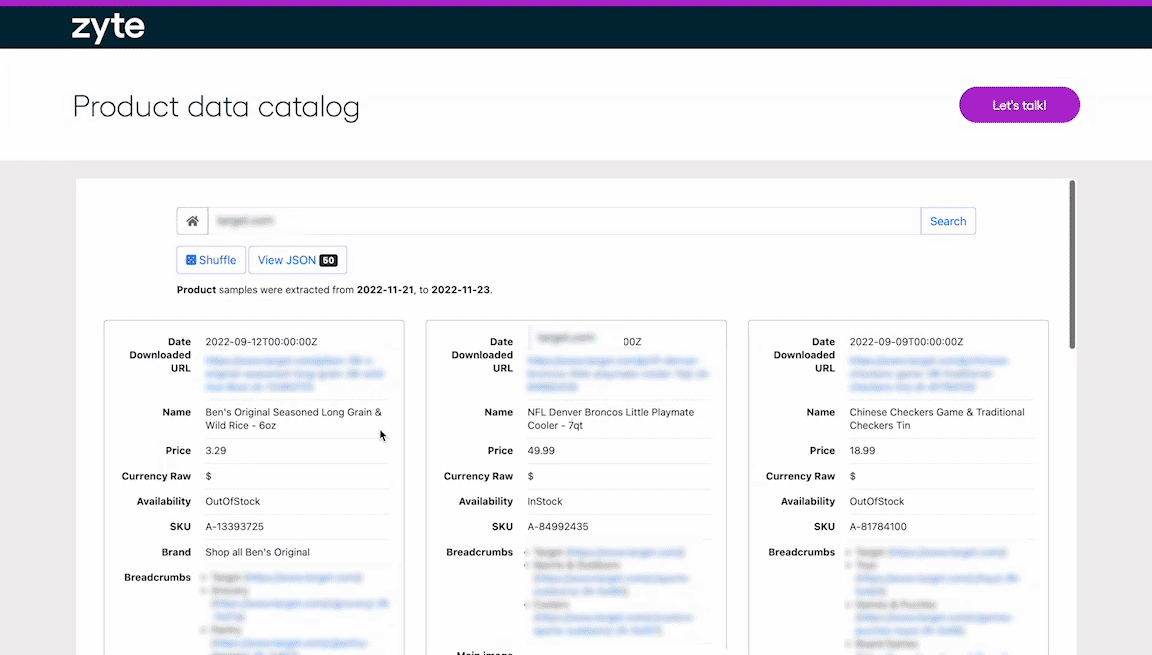
Browse thousands of datasets
Browse our data catalog for sample data from thousands of e-commerce websites to see what we scrape daily.
Web data types
No matter what data type you're looking for, we've got you covered.
Web data use cases
Our delivery team will build the data feeds you need, tailored to your use case. Standard, bespoke and everything in between.
Our data extraction plans are created with your requirements in mind.
To get a price for your project, talk to our team today.
*Set up not included
Website
Any
Choose from over 40,000
Schema
Custom
Standardized
Crawl Frequency
Flexible
Choose your own schedule
Predefined
Select frequency
Delivery
Any Cloud Platform
Amazon S3 Bucket
Format
JSON, CSV and more
JSON Format
Post-Processing
Included
Available as upgrade
Service Level Agreement
Enterprise
24/7 Support
Standard
Support Monday to Friday
Crawl Control
Full control
Fixed
Quality Assurance
99.99%
99.99%
Legal and GDPR
Compliant
Compliant
Our customers love Zyte
Frequently asked questions
Is Zyte the same as Scrapinghub?
Different name. Same company. And with the same passion to deliver the world’s best data extraction service to our customers. We’ve changed our name to show that we’re about more than just web scraping tool. In a changing world Zyte is right at the cutting edge of delivering powerful, easy to use solutions that help our customers stay ahead in today’s fast-moving, data-driven world.
What support do you offer?
We offer all our customers no-cost support on coverage issues, missed deliveries and minor site changes. If there’s a larger website data extraction change that requires a complete spider overhaul this may incur an additional cost.
Can I try Zyte before buying?
Yes, if we have sample data available for the source you want to be scraped. If it’s a new source we haven’t crawled before we will share sample data with you following development kick-off. This occurs post purchasing. For product or news & article data, you can free trial our Automatic Extraction product via an easy-to-use user interface.
Talk to us about your requirements
How can Zyte help me extract website content?
Zyte Data extraction services is an end-to-end solution that can help you with web content extraction. It’s the most hassle-free way to get clean structured data; quickly and accurately. But if you’re looking for a DIY option, Zyte offers web data extraction tools to make your job easier.
What is meant by data extraction?
Data extraction is described as the automated process of obtaining information from a source like a web page, document, file or image. This extracted information is typically stored and structured to allow further processing and analysis.
Extracting data from Internet websites - or a single web page - is often referred to as web scraping. This can be performed manually by a person cutting and pasting content from individual web pages. This is likely to be time-consuming and error-prone for all but the smallest projects.
Hence, data extracting is typically performed by some kind of data extractor - a software application that automatically fetches and extracts data from a web page (or a set of pages) and delivers this information in a neatly formatted structure.
This is most likely a spreadsheet or some kind of machine-readable data exchange format such as JSON or XML. This extracted data can then be used for other purposes, either displayed to humans via some kind of user interface or processed by another program.
Why is data extraction important?
There’s a vast amount of information out there on the Internet. Extracting and aggregating data from public-domain websites and other digital sources - also known as web data scraping - can give you a significant business edge over your competitors.
Data extracting generates insights that can help companies analyze the performance of a particular product in the marketplace, track customer sentiments expressed in online reviews, monitor the health of your brand, generate leads, or compare price information across different marketplaces.
It also gives researchers a powerful tool to study the performance of financial markets and individual companies, guide investment decisions and shape new products.
There are many non-financial uses for data extraction, such as scraping news websites to monitor the quality and accuracy of stories or to monitor trends in reporting. It’s also used to obtain information from public institutions, for example, to track contract awards and hence investigate possible corruption.
Data extraction can significantly streamline the process of getting accurate information from other websites that your own organization needs to survive and thrive.
What is a data extraction example?
There’s a vast range of applications and use cases for website data scraping. One popular example where data extraction is widely used comes from the world of retail and e-commerce. It’s an invaluable tool for competitor price monitoring, allowing companies – and market researchers – to monitor the pricing of rivals’ products and services. Manually tracking competitors’ prices that may change on a daily basis isn’t practical - especially if you’re monitoring the pricing of hundreds or thousands of different products. A data scraping tool automates this process, scraping pricing data from e-marketplaces and competitors’ websites quickly and reliably.