Turn pages into structured data instantly, like magic
End the pain of parsing. Let AI understand the page and extract the data for you.
The hidden cost of writing parsers
Death by DOM
Identifying and testing XPath or CSS selectors is slow and repetitive.
Error-prone
Fragile selectors break when site markup changes.
Slow to scale
Scraping dozens of sites means never-ending maintenance.
Pick your AI superpower
Three ways to turn any web page into valuable data.
Instant extraction from any page
Just get the data. One parameter is all you need. "pageContent": true is your key to instantly extract the main content of any page. No selectors in sight, no HTML to clean up – just clean, slim-line content, ready for LLMs or any use case.
1{
2 "httpResponseBody": true,
3 "pageContent": true,
4}
5
6def parse(self, response):
7 http_response_body: bytes = response.body
8 with open("http_response_body.html", "wb") as fp:
9 fp.write(http_response_body)
10 product = response.raw_api_response["product"]
11 yield product
12}1{
2 "headline": "Royal Victoria Infirmary",
3 "itemMain": "Hospital NHS hospital Royal Victoria Infirmary Queen Victoria Road, Newcastle Upon Tyne, Tyne and Wear, NE1 4LP (0191) 233 6161 Provided and run by: The Newcastle upon Tyne Hospitals NHS Foundation Trust Overview Latest inspection summary All inspection reports and timeline Registration details Map and contact details Get alerts when we inspect Give feedback on care at this service About your care...",
4 // ...,
5 "itemMainXPath": "//*[@id=\"main-content-wrapper\"]",
6 "metadata": {
7 "dateDownloaded":"2025-08-12T16:14:22Z"
8 }
9}Rich, content-specific schemas
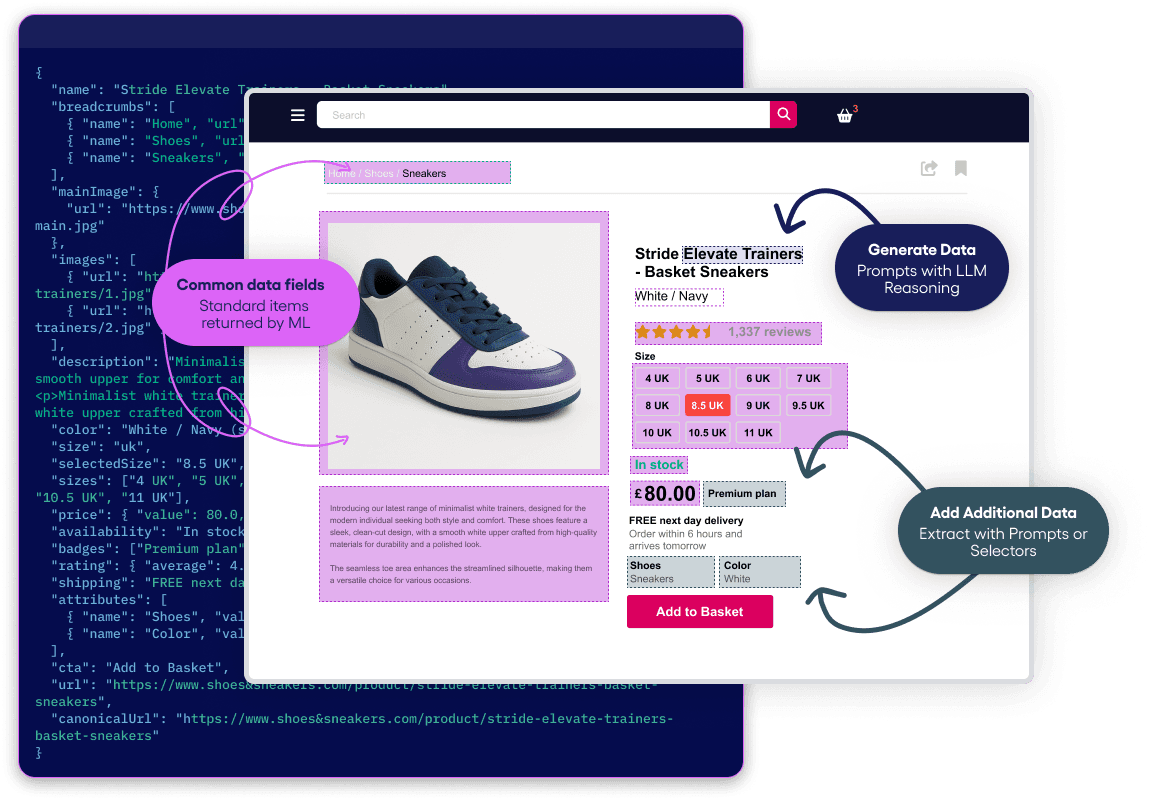
Zyte API uses machine learning models to identify and return standard data schema from a range of specific data types such as Product, Article, Job Posting, Search Engine.
Conjure any field, on command
Our most powerful capability, custom attributes extraction, puts a scraping-tuned Large Language Model at your beck and call.
Extract mode
No more selectors. Use natural language to instruct Zyte API to find and return custom on-page data.
1{
2 "pockets": {
3 "type": "integer",
4 "description": "What is the number of pockets in this garment?"
5 }
6}Generate mode
Go beyond language-based extraction. Summarize, transform or translate captured data before it is even returned.
1{
2 "datetime_posted": {
3 "type": "string",
4 "description": "the date when the article was created, in the following format: YYYY/MM/DD"
5 }
6}Add AI Extraction to your first request
Built to work the way you do
AI Extraction integrates seamlessly with your existing Zyte API workflows.
Plays well with Scrapy
Use AI Extraction directly inside your Scrapy spiders with no extra parsing logic — just one parameter in your request and the data arrives structured."
Domain-trained models
Specialized AI models for ecommerce products, articles, jobs, and search engine results ensure accuracy and efficiency.
Flexible schema
Get common fields by default, then customize the schema to fit your needs. Add or remove fields with either code or natural language prompts.
No-maintenance parsing
Forget fixing brittle selectors when sites change — our AI adapts automatically to evolving page structures.
Simple pricing that
scales with your needs
Explore transparent pricing designed to grow with your needs.
See our pricing plans"Awards, five-star reviews and millions of happy customers"
The results are in: Zyte customers love our products. Check out these views and reviews on independent sites.
It just works
Zyte was able to offer the most simple and effective rotating proxy solution for us. It just works.
Aurélien Jemma
CEO at Liwango
Always there
Collaboration with Zyte has been easy and support was always there throughout our journey.
Ru Hickson
Data Engineer at Kinzen
5 lines of code
It was literally 5 lines of code to get started with Smart Proxy Manager and see crawling success.
Oskar Bruening
CTO at Peek
For successful business
Without Zyte Smart Proxy Manager our business is not successful.
Michael Raburn
Co-Founder of Bridge Below




_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
