In this article, I’llexplain the problem of anti-bot technology for web scraping developers through the lens of the anti-bot distribution curve (a view of the top 250,000 websites and the relative complexity of their anti-bot tech) and the landscape of anti-bot tech across the web. We’ll look at the exact distribution, walk through the consequences and challenges it presents, and show some of the solutions the industry has come up with.
Since the AI revolution and the launch of the new scraping tech categories of ‘site unblockers’ and ‘AI scrapers’ I believe an automation-first approach to solving these challenges is key to helping solve the cost vs speed vs success trade-offs in crawling infrastructure.
Automation, AI and APIs used to be my tools of last resort… These days they are my tools of first resort, and it’s all down to how they solve the trade-offs in cost vs speed vs success within scraping infrastructure.
What causes the cost vs speed vs success trade-off?
Every experienced web scraping developer knows this trade-off whether explicitly or they just feel it in their bones:
Though there are plenty of websites built on the same platforms. Jobs platforms, ecommerce platforms being the two obvious cases, many websites have different levels of anti-bot protection. From non-existent to extremely complex .
The Landscape of Anti-Bot Protection in 2024
In late 2023, Zyte analysed the top 250,000 websites being scraped on the platform and categorised the complexity of the anti-bot technology being used to access the websites across five groups.
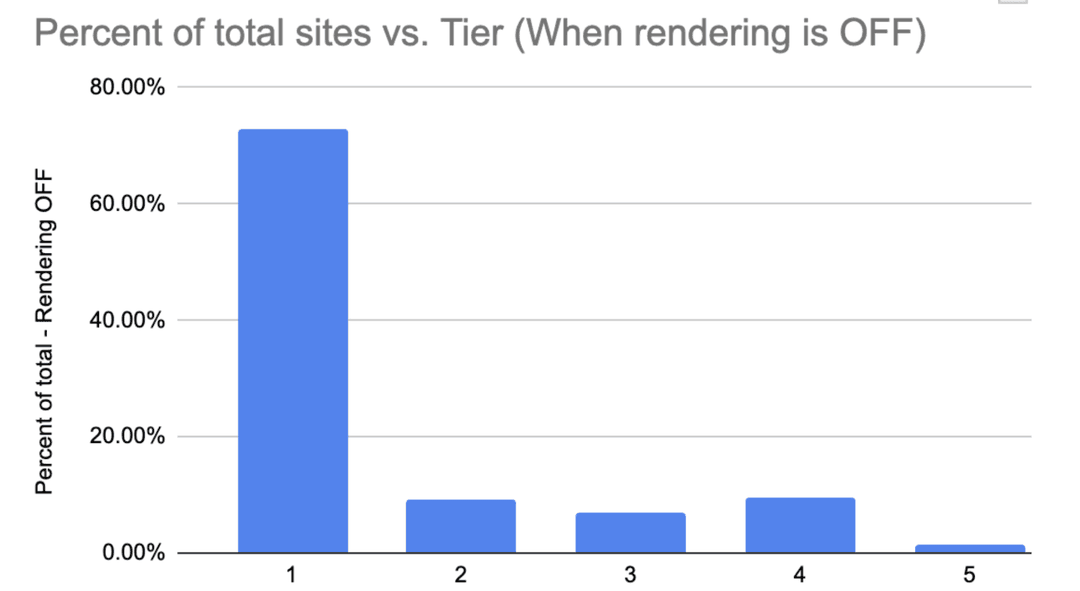
Breakdown of website crawling complexity:
Tiers 1-3 = 88%
Tier 4 = 9.5%
Tier 5 = 1.5%
In the distribution data taken from Zyte API, it shows the relative difficulty of the 250,000 websites grouped into five tiers from the most complex (tier 5) to the simplest (tier 1).
The impact of the variance in difficult-to-access websites is that you need to treat them individually if you want to manage costs effectively. You’re going to have to use different approaches for each website. That requires working out the best approach for each individual website. This means you have to:
spend a lot of time making custom spider code to each individual website,
host a fleet of different browsers on servers,
probably run some platform as a service tech or similar, and
implement monitoring, dashboards and alerts across the tech stack.
Of course, this all takes time and really adds up, especially when each spider or piece of tech in the stack can break at any given moment in time...
So when you look at web scraping as a distribution problem rather than a technology problem the savvy developer can begin to see the choices and compromises you're forced to make — primarily cost vs speed vs success.
Because of the broad distribution of websites along the continuum of simple to difficult, you need to decide if you’re willing to trade off the cost of a project vs the speed and scalability of that project.
Common ways to handle the cost vs speed vs success trade-off?
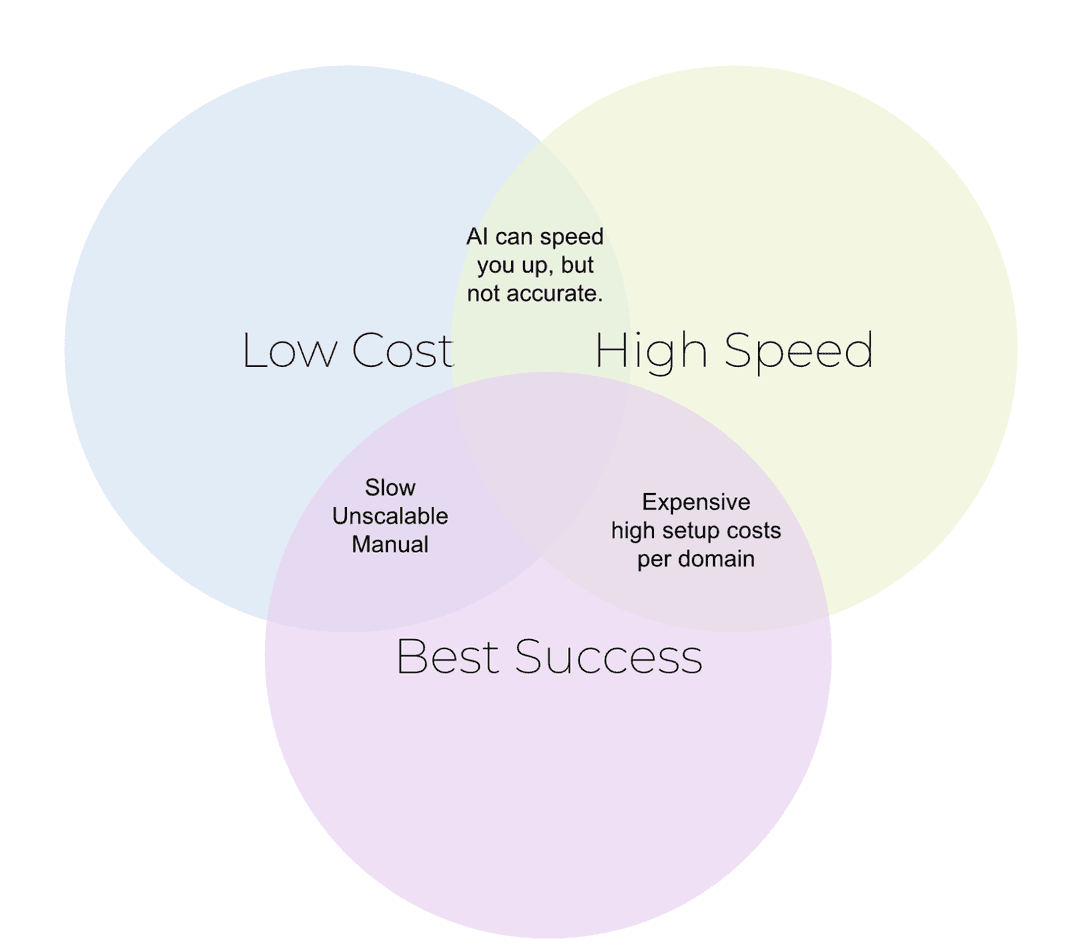
Sledge hammer solutions
If you’re spending a lot of time building or buying a system that is like a hammer and sees every site as a nail, you end up paying for tech you don’t need. This adds up quickly if you are scraping a lot of pages.
Pros: Instant unblocking of the majority of websites
Cons: Expensive and doesn’t scale well
Trade-offs: Sacrifices cost for speed and success
The compromise solution
Building a system that trades off some success for cost efficiency might work well if you’re under little to no time pressure and can constantly revise.
Pros: Cheaper to run than sledge hammer and AI solutions
Cons: Susceptible to missing data and slow crawling
Trade-offs: Sacrifices speed and success for cost
The optimised solution
You can build systems with waterfalls of varying proxy types, browsers and other infrastructure. We’ve even seen generative AI being used to facilitate and speed up developers by being able to manually build crawlers as JSON instructions for a complex optimised system. The issue here is that you’re spending a lot of time and money building a very fragile, multi-vendor system that requires a lot of maintenance and upkeep.
Pros: Instant unblocking of the majority of websites
Cons: Costs a lot to build and maintain and you need highly specialised developers
Trade-offs: Cost efficiency is gained at the high cost of system ownership. Even if you’re building smart systems, with some logic to help navigate the distribution problem, you’re just shunting the problem into a different challenge. You’re swapping the time it takes to scrape websites one by one for the challenge of building a vast scraping system. That system might save your developers time in building and maintaining the actual crawler, but another developer has to balance and maintain a proprietary system created from multiple tools, vendors and internal code bases. So any time savings are diminished because of the total cost of ownership for the entire scraping system.
AI solutions
You can build AI powered or AI augmented solutions that can speed up some aspects of writing web scraping code from spider/crawler creation to selector generation. You can even use large language models (LLM) to parse page data or to write selector code for you.
Pros: You can increase productivity in multiple areas by having AI do some of the manual coding work for you at development time. E.g. help you write selector code or convert JSON into scraping configurations.
Cons: The trade off here is that the LLMs are generally too expensive to run on every page (and they aren’t very accurate for specific fields like SKU or Price), so using LLMs for extraction is out.
Trade-offs: So you are basically just using it to speed up writing selectors, which is nice, but those selectors will break in time, and you'll have to fix them again and again.
Is compromise between cost, speed and success inevitable?
Kind of…
Ultimately, no matter which system you build you’re always going to be tied to one fatal flaw — you're using human power to diagnose, overcome and fix website bans one by one. Your headcount determines your speed and capacity to scale more than any other factor (outside of budget).
Depending on your business and project needs, that might be OK though.
Sometimes it's okay to spend thirty times more per request, when you’re only crawling five websites and 10,000 pages if speed is your priority.
Sometimes you’re only going to extract data from one massive website with tens of millions of pages once per quarter, so you need to have hyper-optimised requests that are super cheap per request for that one website.
However, in the case where you want to extract data from lots of different websites, quickly with high success at a low total cost or without investing in years-long programs of system development, then there are few options. And any solution needs the ability to:
Analyse a website’s anti-bot tech on the fly without (much) human intervention.
Automatically assign the minimum set of resources needed to overcome any ban. It has to be cheaper or cheaper for the easy sites and appropriately priced for the more difficult ones.
Monitor and self-correct over time.
Access to the infrastructure required to access the websites and return the data (Proxies, browsers, stealth tech, cookie management, etc).
Work using an API to interact, customise and control the solution via a scraping framework like Scrapy.
Have a pricing model that adjusts to each site's costs individually.
Failure to have any one of these will doom any website unblocking system to the cost vs speed vs success trade off and crush your ability to collect web data at scale. You’ll be bogged down with upfront work unblocking spiders and then monitoring and maintaining their health.
I believe Zyte has a solution
Zyte API (LinkedIn Zyte API) was built with the above criteria baked into its DNA. It's an API with fully hosted infrastructure that unblocks the vast majority of sites out of the box with a simple API call. You can integrate it as part of your optimised system or outsource all your requests to it and focus on working with the data it returns.
It’s not a silver bullet, but it is definitely automation that will massively boost productivity.
Pros: All the benefits of an optimised solution without any of the trade-offs and lower total cost of ownership
Cons: Automated systems aren’t perfect so domain experts are needed to operate and for tweaking of the system.
Trade-offs: You have to trust Zyte.
Zyte doesn’t promise it’s a silver bullet for all websites, but we do promise Zyte API will
automatically unblock a large number of your websites for you,
unblock those websites using the right technology at the right price across the full anti-bot distribution curve, and
offer all the features you need to keep your developers as “humans in the loop” to handle anything it can’t using your team’s deep domain expertise.
Zyte’s approach is not only faster to build with but also has the best pricing model for targeting a mix of all different website types:
“Zyte’s pricing is interesting in general. The provider adjusts request cost dynamically, based on the website’s difficulty and optional parameters. This means your rates may become more or less expensive over time, even when accessing the same website…. Zyte’s dynamic pricing proved to be the least expensive in scenarios that didn’t require JavaScript. Otherwise, the other request-based providers gave it a tough competition.”
Chris Becker, Proxy reviewer and tester. proxyway.com
Interested in learning more about Zyte API’s powerful ban handling features, watch the video to learn more and sign-up for a free trial. (LinkedIn sign-up for a free trial)
Try Zyte API
Zyte proxies and smart browser tech rolled into a single API.






_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
