
A practical guide to web data QA part I: Validation techniques
When it comes to web scraping at scale, there’s a set of challenges you need to overcome to extract the data. But once you are able to get it, you still have work to do. You need to have a data QA process in place. Data quality becomes especially crucial if you’re extracting high volumes of data from the web regularly and your team’s success depends on the quality of the scraped data.
This article is the first of a four-part series on how to maximize web scraped data quality. We are going to share with you all the techniques, tricks, and technologies we use at Scrapinghub to extract web data from billions of pages every month while keeping data quality high.
Step #1: Understand requirements and make them testable
The first step is to understand the business requirements of the web scraping project and define clear, testable rules which will help you detect data quality problems. Understanding requirements clearly is essential to move forward and develop the best data quality process.
Requirements are often incomplete, ambiguous, or vague. Here you can find some general tips for defining good requirements:
- use proven techniques such as JSON schema
- use specific and clear rules
- resolve controversial points
In order to show an actual example, in this article we are going to work with product data that was extracted from an e-commerce site. Here is a sample of what two typical scraped records are intended to look like:

In addition to these sample records, the business requirements - that are provided to the QA Engineer - are as follows:
- mandatory fields:
- url
- price
- product Id
- product name
- price must be a number
- url must be unique
- date - it's should be formatted as a date
- remove extra white-spaces, HTML tags, CSS, etc
Can you find some potential problems with the requirements above?
The stipulation on a data type for field price seems at first glance to be sufficient. Not quite. Is "2.6" valid? Or should it be 2.6? The answer is important if we want to properly validate. “We scraped the right thing, but did we scrape it right?”.
Similarly, there are 3 different date formats that will satisfy ISO 8601. Should we report warnings for the following if scraped?
- 10 March
- 14/03/2020
- 2020/03/15 22:00
Take a minute and try to visually validate this data based on the rules above. See how your validation fares against the automated validation techniques that will be outlined below.
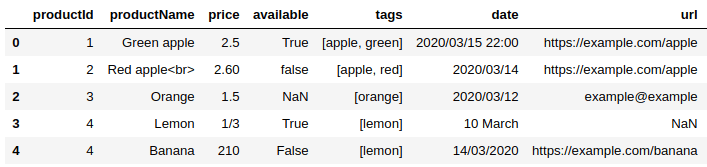
Below are some example scraped records for this scraper and its requirements. For illustrative purposes, only the first record can be deemed to be of good quality; the other four each exhibit one or more data quality issues. Later on in the article we will show how each of these issues can be uncovered with one or more automated data validation techniques.
Step #2: JSON schema definition
Based on the requirements outlined above, we are going to define a JSON schema that will help us to validate data.
If a schema is not created by hand in advance of spider development, one can be inferred from some known representative records using a tool like GenSON. It’s worth pointing out that although such inference is convenient, the schemas produced are often lacking the robustness needed to fully validate the web scraping requirements. This is where the experience of the QA Engineer comes into play, taking advantage of more advanced features of the JSON Schema standard, as well as adding regex’s and other more stringent validation, such as:
Defining mandatory fields
By default, all fields are marked as mandatory - at the end, only the ones requested from the client will be left
Defining unique fields
In the current version of JSON schema standard, it is not possible to enforce uniqueness.. While future drafts may support it, currently it is necessary to work around this by inserting a keyword that an automated data validation framework will recognize. In our case, we will use the keyword “unique”.
Add special formats for dates and prices
Some examples:
Price:
- "^[0-9]*.[0-9]{2}$"
- "^[0-9]+(\.[0-9]+)?$"
Date:
- "^[0-9]{4}(-[0-9]{2}){2}T([0-9]{2}:){2}[0-9]{2}\.[0-9]+$"
- "(\d{4})-(\d{2})-(\d{2}) (\d{2}):(\d{2}):(\d{2})"
- "^20[0-9]{2}-[01][0-9]-[0-3][0-9]$"
This is what the final schema looks like:
Plain text
Copy to clipboard
Open code in new window
EnlighterJS 3 Syntax Highlighter
{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "product.json", "definitions": { "url": { "type": "string", "pattern": "^https?://(www\.)?[a-z0-9.-]*\.[a-z]{2,}([^>%\x20\x00-\x1f\x7F]|%[0-9a-fA-F]{2})*$" } }, "additionalProperties": true, "type": "object", "properties": { "productId": { "type": "integer", "unique": "yes" }, "productName": { "type": "string" }, "price": { "type": "number" }, "tags": { "type": "array", "items": { "type": "string" } }, "available": { "type": "boolean" }, "date": { "type": "string", "format": "datetime" }, "url": { "$ref": "#/definitions/url", "unique": "yes" } }, "required": [ "price", "productId", "productName", "url" ] }
{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "product.json", "definitions": { "url": { "type": "string", "pattern": "^https?://(www\.)?[a-z0-9.-]*\.[a-z]{2,}([^>%\x20\x00-\x1f\x7F]|%[0-9a-fA-F]{2})*$" } }, "additionalProperties": true, "type": "object", "properties": { "productId": { "type": "integer", "unique": "yes" }, "productName": { "type": "string" }, "price": { "type": "number" }, "tags": { "type": "array", "items": { "type": "string" } }, "available": { "type": "boolean" }, "date": { "type": "string", "format": "datetime" }, "url": { "$ref": "#/definitions/url", "unique": "yes" } }, "required": [ "price", "productId", "productName", "url" ] }
1{ "$schema": "http://json-schema.org/draft-07/schema#", "title": "product.json", "definitions": { "url": { "type": "string", "pattern": "^https?://(www\\.)?\[a-z0-9.-\]\*\\.\[a-z\]{2,}(\[^>%\\x20\\x00-\\x1f\\x7F\]|%\[0-9a-fA-F\]{2})\*$" } }, "additionalProperties": true, "type": "object", "properties": { "productId": { "type": "integer", "unique": "yes" }, "productName": { "type": "string" }, "price": { "type": "number" }, "tags": { "type": "array", "items": { "type": "string" } }, "available": { "type": "boolean" }, "date": { "type": "string", "format": "datetime" }, "url": { "$ref": "#/definitions/url", "unique": "yes" } }, "required": \[ "price", "productId", "productName", "url" \] }Step #3: Schema validation against the scraped data
With requirements clarified and subsequently mapped to a robust schema with stringent validation, the core ingredient for automated data validation is now in place. The Python library jsonschema will be used as part of a broader automated data validation framework built upon the Robot framework and leveraging Pandas for additional, more advanced data analysis.
Given the schema and sample data defined above, the validation processes clearly shows us the data quality issues that need to be investigated:
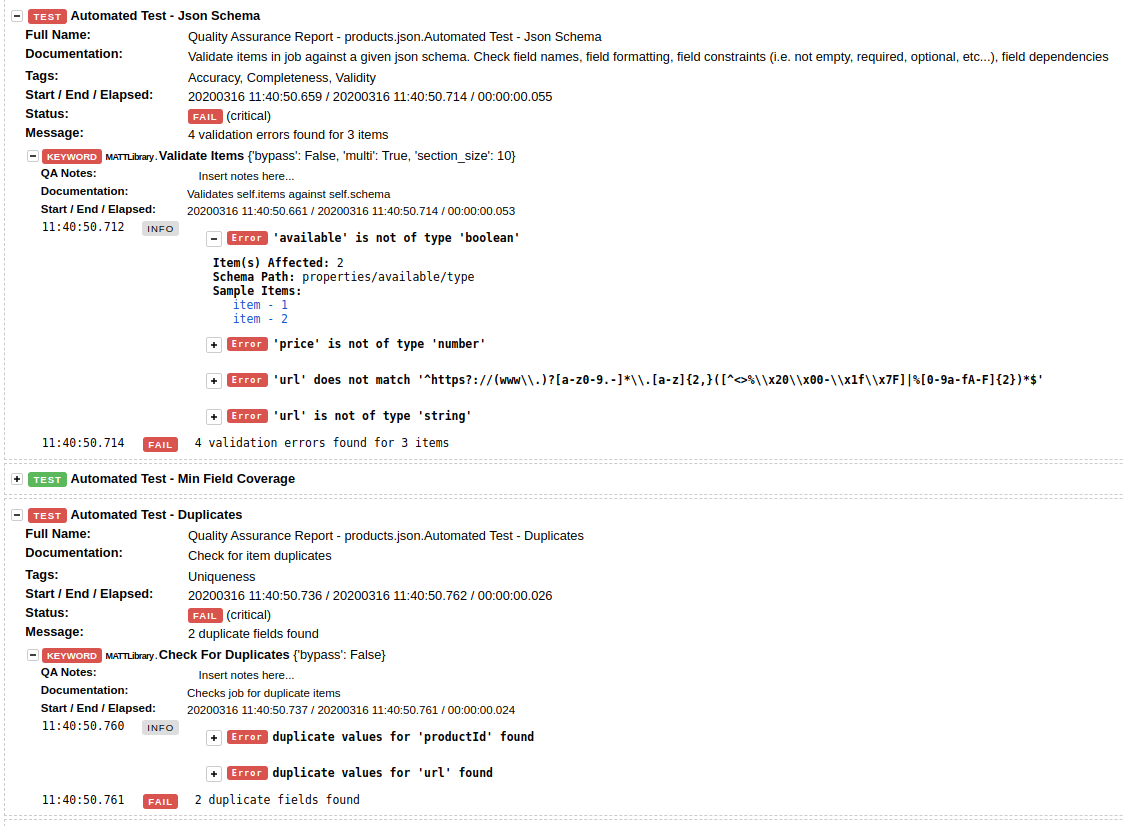
Let's discuss some of them in more detail:
- available is not of type 'boolean' - Looking at the data for the reported items we can find that values indeed don't satisfy the expected type. In case of missing values for a given field this should be defined in the schema itself thus: "type": ["boolean", "null"].
- "False" is not a valid boolean value. The correct value should be false.
- price is not of type 'number' - Can you find what else might be wrong beyond the format? We will answer this question in the next section.
- "2.6" - if price is stored as string it might cause unexpected results for further data consumption or operation on the whole price data.
- url does not match the specified regex. Regex’s for URL validation are usually an amalgam of standard validation (for the presence of ‘http://” etc.) as well as any additional business requirements around e.g. categories, query params, pagination etc.
- example@example is clearly not a valid URL.
- duplicate values for url found - the validation shows that some items have duplicate URLs. URL is a field that should (normally) be unique and not repeated throughout the dataset.

- field productName contains HTML tags: ['
'] - Red apple - field productName contains superfluous characters (in this case, trailing and/or leading whitespace). It is worth noting that while visual inspection of data either in a browser or in tabular form in e.g. Excel can be useful in the detection of some types of issues, this is one that can easily go undetected to the human eye.
Step #4: More advanced automated data analysis
Although schema validation takes care of a lot of the heavy lifting with respect to checking the quality of a dataset, it is often necessary to wrangle and analyze the data further. Either to sense-check schema validation errors, discern edge cases and patterns, or test more complex spider requirements.
Pandas is often the first port of call, for its ability to concisely:
- replicate SQL queries
- aggregate stats
- find the top results per data point or group of fields
- plot useful diagrams
- deal with nested data
- highlight unique values and detect duplicates
- replicate Excel’s pivot table functionality
- and more...
In the following examples, df is a scraped dataset represented as a Pandas DataFrame.
Finding outliers in the field “price” (1)
Before manipulating the data, it is often useful to see a high-level overview of it. One way is to list the top values for all fields using value_counts() in conjunction with head():
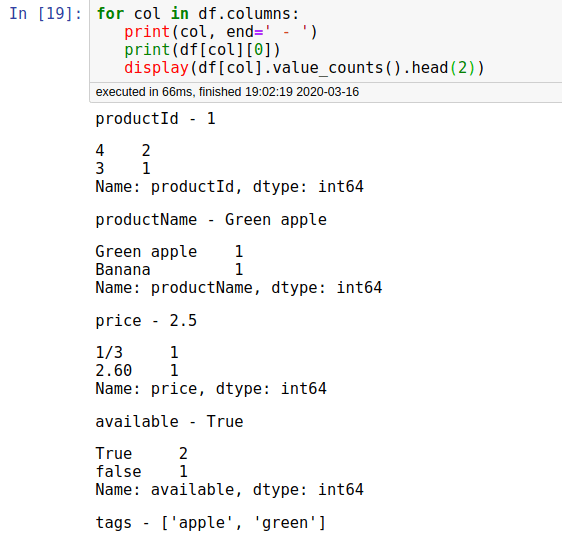
Finding outliers in the field “price” (2)
In the price data point there are several problems:
- Mixed values - string and numeric
- Potentially incorrect values like 210
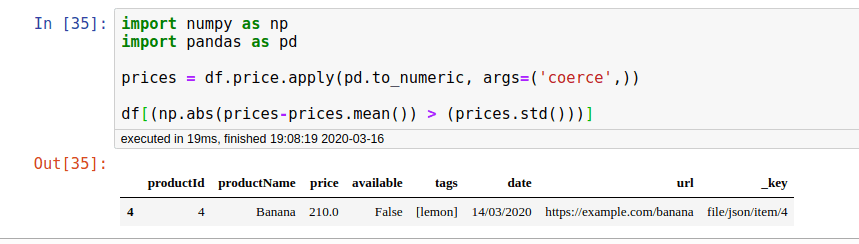
The first step is to get all prices scraped as numeric:
prices = df.price.apply(pd.to_numeric, args=('coerce',))
We then determine mean and standard deviation:
- prices.std()
- prices.mean()
And finally to find all values which are too far from the standard deviation:
Extract the first tag of nested column
The next possible source of error is tags and names. Let's try to find if there are any cases where tags are not part of the name. In this case, we will expand nested data and iterate over the values.
tags = df.tags.apply(pd.Series)
Then we can access the first tag thus:
tags[0]

Conclusions
In this article, our goal was to give an overview of how data extracted from the web can be validated using whole-dataset automated techniques. Everything we’ve written about is based on our experience validating millions of records on a daily basis.
In the next post in the series, we’ll discuss more advanced data analysis techniques using Pandas as well as jq, with more real-world examples. We’ll also give an introduction to visualization as a way of uncovering data quality issues. Stay tuned!
Do you need help with web data extraction?
Data quality assurance is just one small (but important!) piece of the puzzle. If you need help with your whole web data extraction project and you’re looking for a reliable data partner, have a look at our solutions or contact us to get started!







_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
