
Mapping corruption in the Panama papers with open data
We are at a point in the digital age where corruption is increasingly difficult to hide. Information leaks are abundant and shocking.
We rely on whistleblowers for many of these leaks. They have access to confidential information that’s impossible to obtain elsewhere. However, we also live in a time where data is more open and accessible than at any other point in history. With the rise of Open Data, people can no longer shred away their misdeeds. Nothing is ever truly deleted from the internet.
It might surprise you how many insights into corruption and graft are hiding in plain sight through openly available information. The only barriers are clunky websites, inexperience in data extraction, and unfamiliarity with data analysis tools.
We now collectively have the resources to produce our own Panama Papers. Not just as one offs, but as regular accountability checks to those in situations of power. This is especially the case if we combine our information to create further links.
One example of this democratization of information is a recent project in Peru called Manolo and its intersection with the Panama Papers. Manolo used the webscraping of open data to collect information on Peruvian government officials and lobbyists.
Manolo
Manolo is a web application that uses Scrapy to extract records (2.2 million so far) of the visitors frequenting several Peruvian state institutions. It then repackages the data into an easily searchable interface, unlike the government websites.
Peruvian journalists frequently use Manolo. It has even helped them uncover illegal lobbying by tracking the visits of construction company representatives who are currently under investigation to specific government officials.
Developed by Carlos Peña, a Zyte engineer, Manolo is a prime example of what a private citizen can accomplish. By opening access to the Peruvian media, this project has opened up a much needed conversation about transparency and accountability in Peru.
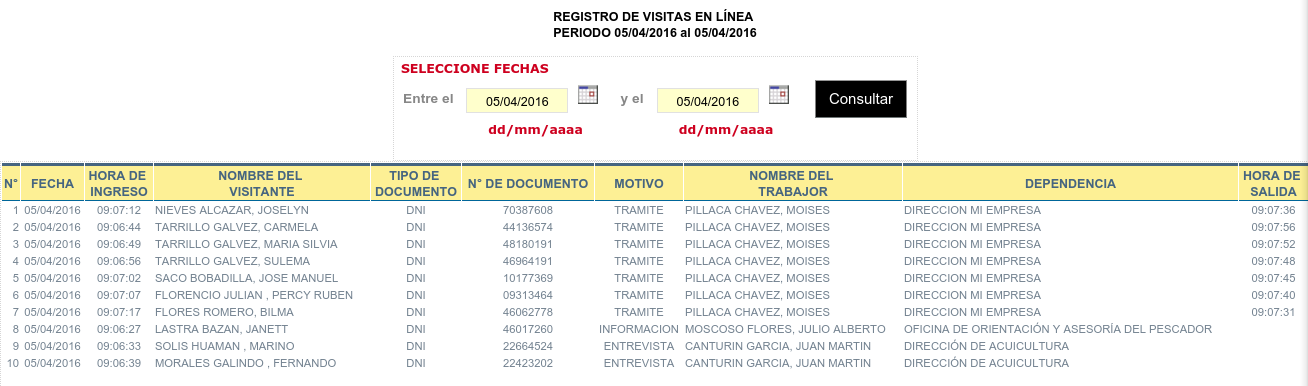
Clunky government website
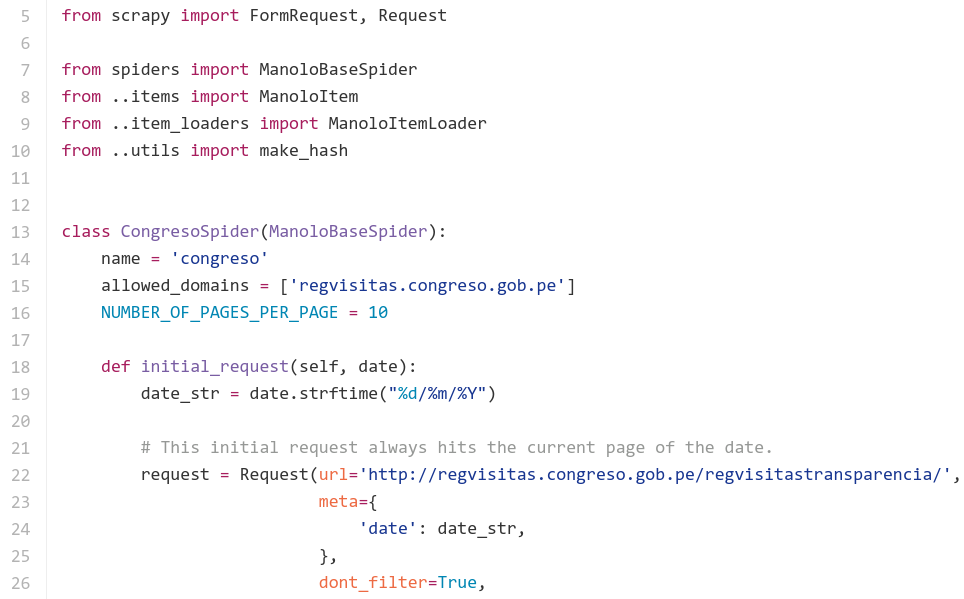
Scrapy working its magic
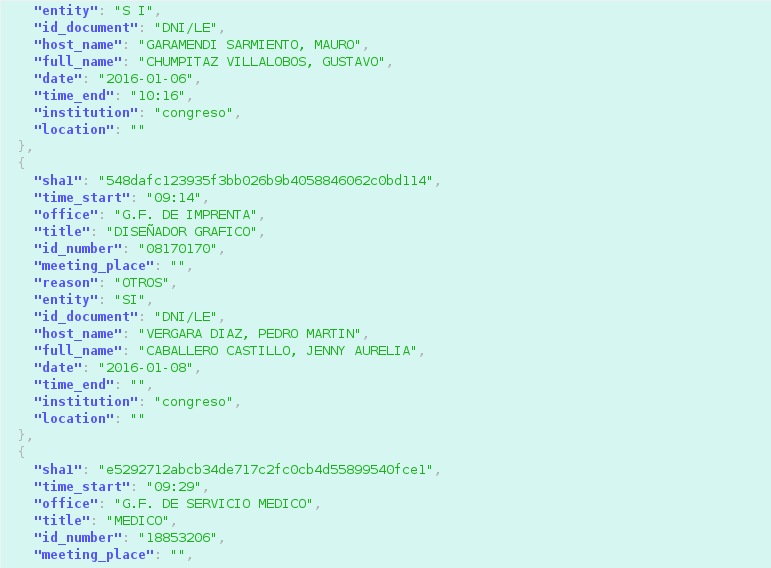
Extracted data in a structured format
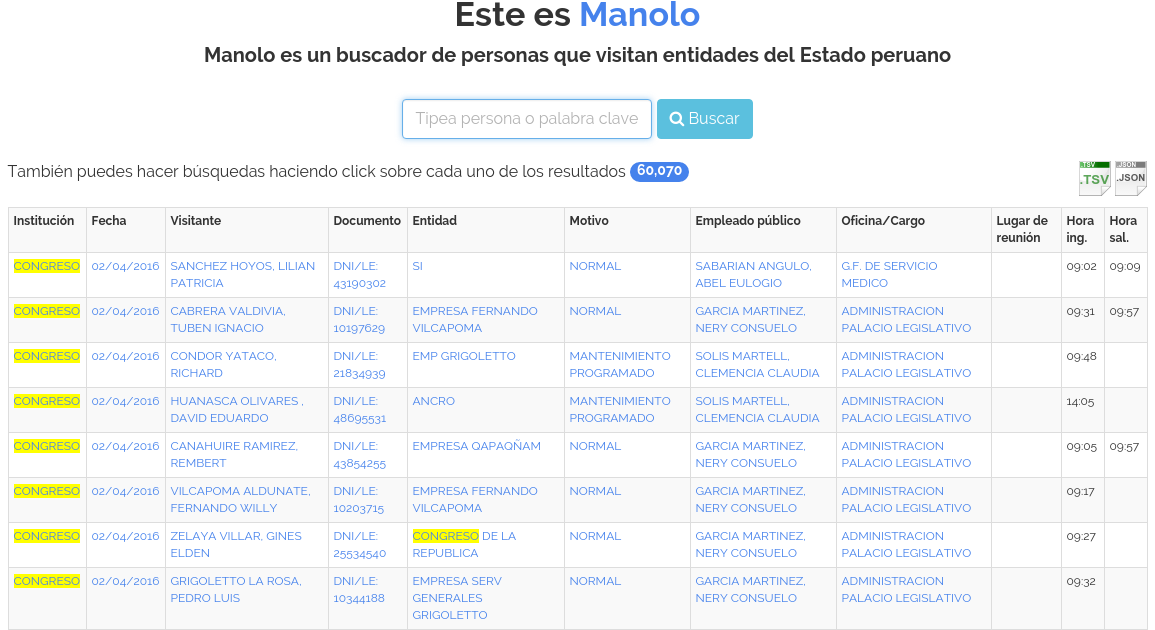
Final transformation into Manolo
Cross-Referencing Datasets
With leaks like the Panama Papers as a starting point, web scraping can be used to build datasets to discover wrongdoing and to call out corrupt officials.
For example, you could cross-reference names and facts from the Panama Papers with the data that you retrieve via web scraping. This would give you more context and could lead to you discovering more findings.
We actually tested this out ourselves with Manolo. One of the names found in the Panama Papers is Virgilio Acuña Peralta, currently a Peruvian congressman. We found his name in Manolo’s database since he visited the Ministry of Mining last year.

According to the Peruvian news publication Ojo Público, Acuña wanted to use Mossack Fonseca to reactivate an offshore company that he could use to secure construction contracts with the Peruvian state. As a congressman, this is illegal. In Peru, there are efforts to investigate Virgilio Acuña and his brother, who recently ran for president, for money laundering.

Virgilio Acuña, congressman (middle), on the right Cesar Acuña (campaigning for the Peruvian presidency last month) [Photo via @Ojo_Publico]
Another name reported in the Panama Papers by Ojo Público was Jaime Carbajal Peréz, a close associate of former Peruvian president Alan García.
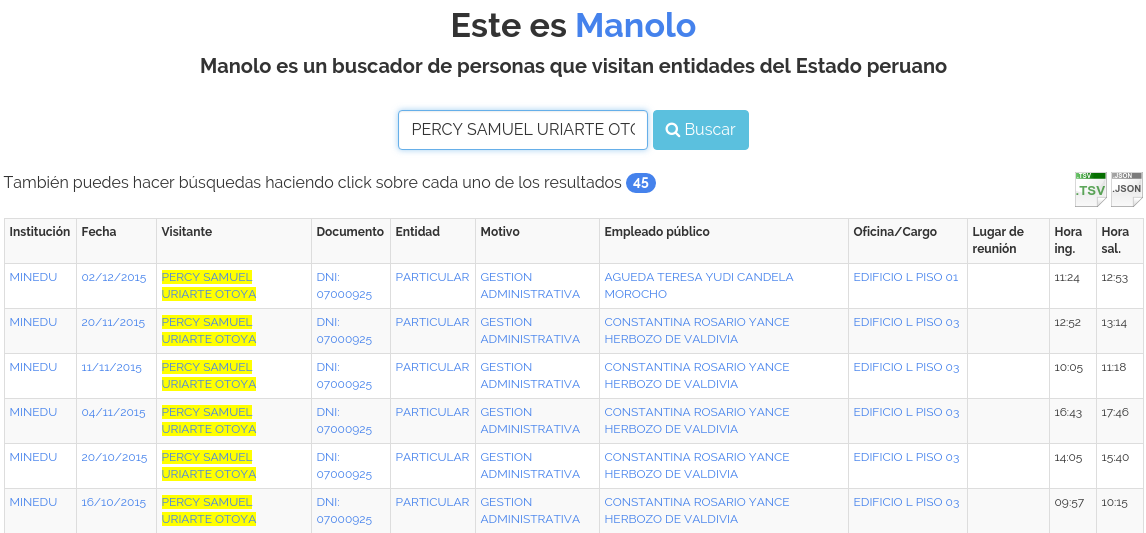
Ojo Público states that in 2008, Carbajal, along with colleague Percy Uriarte and others, bought the offshore company Winscombe Management Corp. from Mossack Fonseca. Carbajal and Uriarte own a business that sells books to state-run schools. Further plot twist is that the third owner of the bookstore, José Antonio Chang, was the Minister of Education from 2006 to 2011 and the Prime Minister from 2010 to 2011.
A quick search of the Manolo database reveals that Percy Uriarte visited the Peruvian Ministry of Education 45 times between 2013 and 2015. IDL-Reporteros, another Peruvian news outlet, reported that the company led by Carbajal illegally sold books to the Peruvian government in 2010. He used a front company for these transactions since he was forbidden by law to engage in contracts with the state due to his close association with the former president.
Data Mining
Data from previous leaks such as the Saudi Cables, Swiss Leaks and the Offshore Leaks have been released publicly. In many cases, the data has been indexed and catalogued, making it easy for you to navigate and search it. And now we’re just waiting on the full data dump from the Panama Papers leaks.
You can use information retrieval techniques to dig deeper into the leaks.You could find matching records, sift through the data by tagging specific words, parts of speech, or phrases, and identify different entities like institutions or people.
Creating Open Data
If the information is not readily available in a convenient database, then you can always explore open data yourself:
- Identify sources of open data that have the information you need. These are often government websites and public records.
- Scrape the data. You can do this in two ways: using a visual web scraper like Portia (no programming needed) or a framework like Scrapy that allows you to customize your code. Big bonus is that these are both open source tools and completely free.
- Download your data and import into your favorite data analysis software. Then start digging!
- Package your findings by creating visual representations of the data with tools like Tableau or Plot.ly.
We actually offer platform integrations with Machine Learning programs like BigML and MonkeyLearn. We’re looking into integrating more data tools later this year, so keep an eye out!
Wrap Up
Data and corruption are everywhere and they can both seem difficult to access.That’s where web scraping comes in. We are a point where citizens have the tools necessary to hold elected officials, businesses, and folks in power accountable for illegal and corrupt actions. By increasing transparency and creating further links between information leaks and readily available data, we can remove the loopholes where firms like Mossack Fonseca exist.
Frameworks like Scrapy are great for those who know how to code, but there shouldn’t be a barrier to acquiring data. Journalists who wish to take advantage of these vast sources of information can use visual web scrapers like Portia to get the data for current and future investigations.




_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
