
News & article data extraction: Open source vs closed source solutions
Article extraction is the process of extracting data fields from an article page and putting it into a machine-readable structured format like JSON. In many use cases, the article page that you want to extract is a news page but it can be any other type of article. Based on our experience in the web data extraction industry for over 10 years, the demand for structured article data is getting higher. There is more information available on the internet than ever. But still, having access to structured news data and being able to consume relevant and timely information can set you apart and give you a competitive edge. This is what article extraction can do for you.
In order to extract article data from the web, you need an extraction tool. It can be a challenge to find the tool that is best suited to meet your needs and provides the functionality and data quality that you expect. In this article, we discuss the most used tools for article extraction that you can choose from.
We’re going to look at both open source and commercial solutions. Hopefully, by the end of this blog post, you will have a better understanding of the available article extraction tools and you will be able to make an educated decision whether an open-source or closed-source tool is the best for you to extract news and/or articles.

Article extraction overview
Before looking at the tools, let’s have a quick overview of what is included in article extraction and why you would extract articles.
Data fields
An article’s most important data field and many times the reason you want to extract the data is the text body field, which contains the text of the article. But other than the text body, there are many other fields you can and might want to extract.
Article extraction fields:
- Headline
- Article body (text)
- Cleaned HTML
- Publication date
- Authors
- Main image
- Other images
Use cases
At Zyte , we’ve seen numerous web data extraction projects that included article extraction.
Example use cases for article extraction:
- News and article monitoring, analytics
- Brand monitoring, mentions, and sentiment analysis
- Competitive intelligence, product launches, mergers and acquisitions
- Generating dataset to train machine learning models for NLP
- Media personalization, summarization, topic extraction, curation
As you can see, article data can provide the most value when building on top of it. But in order to achieve this, you need a reliable way to get structured article data feeds.
An important requirement for any article extraction tool is that it needs to work for most websites without writing any site-specific code. The reason for this is that writing custom rule-based extraction code requires a lot of maintenance, especially if you’re extracting data from hundreds or thousands of domains.
Now let’s look at the available tools!
Open source solutions
When searching for the best tool for any problem, you can be almost sure that there’s an open-source library for that. That’s the case for article extraction as well. Generally though, with open-source libraries, you always need to compromise on some functionality or quality compared to commercial solutions. Regarding OSS article extraction tools, there are quite a few libraries that you can choose from.

Readability
Readability is a library that extracts the main body text from the HTML and cleans it. This is a Python port of a Ruby port of arc90's readability project. It uses heuristics to determine which HTML elements belong to the article’s body.
Newspaper3k
Newspaper3k is a Python 3 library that can extract and curate articles. It can also detect language automatically. It can extract a lot of fields from the article using its handy API.
Dragnet
Dragnet is Moz’s open-source solution to extract articles. The library is based on machine learning models.
Boilerpipe
Biolerpipe is a Python wrapper around a Java library that removes boilerplate code and extracts text from HTML pages. It uses linguistically-motivated heuristics to determine the article body boundaries.
Html-text
Html-text extracts the full text from an HTML page. It does not try to separate the article body from the rest of the page, instead, giving all text present on the page.
Generally, open-source article extraction solutions provide worse results than commercial ones. Even though for some use cases, they still can be good enough if unclean data is acceptable. If your goal is to just get all the content without missing anything, use html-text or a similar “dumb” library. Keep in mind that simple HTML to clean text conversion is surprisingly tricky. Straightforward solutions like the Xpath string() function can produce messy whitespaces, missing or additional text.
Why is machine learning a good fit for article extraction?
The go-to solution for extracting information from a web page is writing some custom code to do the job. A common choice is to write code in Python which then extracts information using XPath or CSS selectors, or sometimes traversing the HTML structure directly. This works well if you want to extract information from a single website with well-defined fields (e.g. product prices) where an XPath selector might look something like ‘//div[@id=”price”]’ - that is, find a “div” element with “id” equal to “price”.
This works well, provided the website has such an element, with the main drawbacks being the time it takes to write and test manual extraction code, and the need to update the code when the website changes. Still, it’s a fine approach in many cases, although it can quickly break when you’re dealing with thousands of websites.
But such an approach often does not work well even for a single website in the case of articles, not speaking of thousands of websites. Why is that? The reason is that even when we find the HTML element which contains the article text, extracting all text from this element often leads to poor results, as this element often contains a lot of unnecessary text, such as author information, advertisements, links to “related” articles from the same platform, comments, tags, forms to subscribe, social network share buttons, etc. While some of these elements could be useful on their own, they are definitely not part of the clean article text and must be removed. But the rules for removal of such elements are quite hard to define, e.g. many of the above elements could be under just ordinary “p” (paragraph) or “ul” (list) tags, and such rules would be often hard to scale from one page of the same website to another.

Machine learning shines when such rules become too hard to maintain. With ML, instead of writing and maintaining thousands of rules, we create an annotated dataset, where we can specify the desired extraction result for each page in the dataset. Then the machine learning model is trained on the dataset, automatically deriving a set of features and weights that generalize well across different pages and websites. The resulting model can be applied to a new website without any tuning, providing good out-of-the-box quality, and allowing to collect articles from tens of thousands of sources.
Commercial solutions
Zyte Automatic Extraction news API
Zyte Automatic Extraction news API is an automatic tool to extract structured articles. News API only needs the page URLs you want to extract the article from and then delivers the structured data. Main features include:
- Simple RESTful JSON API
- Language agnostic
- Javascript execution (if needed)
- Support
- Unlimited Scale
Diffbot
Diffbot’s Article API extracts clean text from news articles.
Webhose
Webhose turns unstructured web content into machine-readable data feeds.
Niche-specific commercial solutions
When it comes to article extraction there are some solutions that specialize in a specific niche. These solutions, going a step further from getting you access to structured data feeds, also provide some kind of textual analysis or analytics on top of the data. These providers usually specialize in the financial industry where relevant and timely information is key to success.
Some considerations for niche-specific article extraction services:
- Only useful, if you are in the target sector (e.g. finance)
- Only monitors specific websites
- No additional value, if you want only data and do your own analysis
Extraction quality comparison
When it comes to web data extraction, data quality is always a key factor. At Zyte , we continuously monitor the quality of news data extracted from Automatic Extraction API against benchmarks and other tools. We also created an in-depth evaluation of the extraction quality provided by the most popular article extraction tools.
In this whitepaper, you can learn about what metrics are important when measuring article body quality and it might help you choose your article extraction tool.
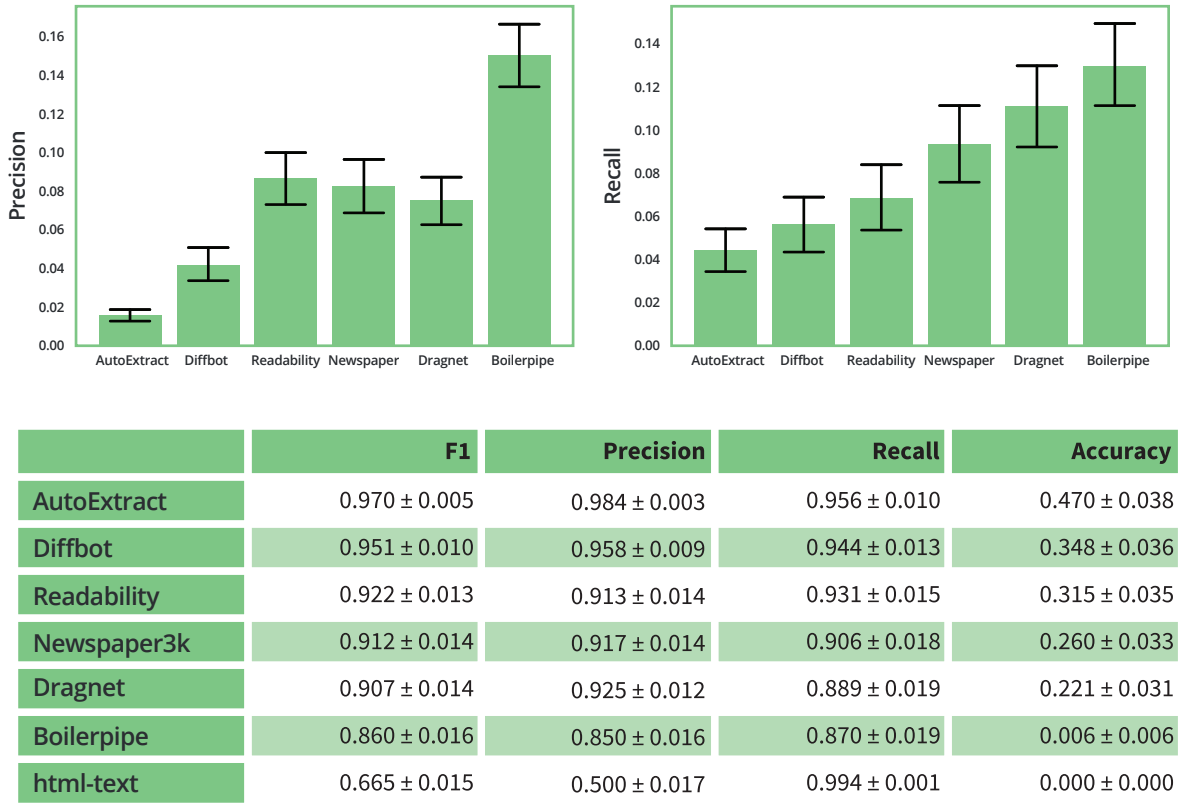
Article body extraction quality is crucial if your business depends on this kind of data. If you’re developing a product or software that needs structured article/news data constantly, you need to make sure you choose a solution that has the best quality on the market. This is what our whitepaper helps you with.
Benefits of commercial solutions
Commercial solutions do provide better quality, as you can see in our evaluation. Besides better quality, commercial services provide other features as well. For example, Zyte Automatic Extraction News API can get you cleaned and normalized HTML of the article, article author, headline, date posted, images, and many other attributes. It can also handle downloading, which is a whole different aspect and significantly affects the final result.
Quality
As discussed above, commercial solutions do provide better extraction quality, which is crucial for many use cases.
Clean HTML
Furthermore, a commercial service like Zyte Automatic Extraction can also extract cleaned and normalized HTML of the article, including article author, headline, publishing date, images, and many other attributes.
Downloading
Downloading HTML files can seem easy but in reality, it has a lot of challenges like javascript rendering and proxy management. Commercial services take care of HTML downloading as well.
Conclusion
Based on our research, it’s safe to say that the quality of article extraction is significantly worse when using open source libraries. Even the most precise open-source library provides 4.6x more unwanted content in the results while missing 2.5x more content than Zyte Automatic Extraction news API. That being said, open-source libraries still can be useful in some use cases where unclean or messy data is acceptable to meet requirements.
Learn more about article extraction
- Extracting article & news data: The importance of data quality
- Extract news at scale at the click of a button
- Custom crawling & News API: designing a web scraping solution
- News web data extraction to predict Irish election results
- Extracting clean article HTML with News API
- News data extraction at scale with AI powered Zyte Automatic Extraction




_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
