
The web is an ocean of information – but, for years, some have been fishing with nets full of holes.
Businesses, researchers, and anyone seeking knowledge from the web's vast expanse have faced the same frustrating challenge: extracting the specific data they need, in a usable format, without getting tangled in a mess of code.
Traditional web scraping, with its reliance on brittle regular expressions, XPath, and CSS selectors, felt like building a house on a foundation of shifting sands. Website structure changes would break scrapers, custom needs required custom code, and scaling became a major headache.
But now a fundamental new shift is underway, driven by the power of Large Language Models (LLMs). We're moving from rigid, rule-based extraction to a more semantic, understanding-based approach – and it's changing everything.
The promise of semantic understanding
For some of us who chat with them, LLMs, like those powering ChatGPT and others, no longer feel like magic – but, for interacting with data, they represent a whole new paradigm.
LLMs’ core strength lies in their ability to understand natural language. This is revolutionary for web scraping because, instead of telling a scraper where to find data on a page (using those often-fragile selectors), we can now simply tell it what data we need.
Underlying this capability are transformers, which allow LLMs to process and understand the relationships between words in a sentence and across entire documents. While a deep dive into the technical details isn't necessary here, it's important to grasp that LLMs aren't just pattern-matching; they're building a model of world understanding.
Zyte's journey – from skepticism to transformation
Zyte has leveraged AI to help data acquisition since 2019. We fed annotated page data to machine learning models to train our engine to extract data from certain content types automatically.
That has allowed us to launch features helping our users quickly extract data from particular, specified data types – including articles, jobs, products, ecommerce listings and search results – in standardized schemas. Many of our customers love using these capabilities today.
At the time, this was the cheapest and best way to access data from the web without parsing it manually, offering many advantages such as accelerating time to data across huge numbers of site types, reducing maintenance costs on parsing, and opening up avenues to large horizontal scale.
Easy data in custom schemas
But those standard schemas don’t cover everything. Data gatherers often need very specific page data – say, an ingredients list, delivery cost, a list of product tags, or even an analysis of the target audience for a product – that don’t fit neatly into any pre-existing schema. Such requirements could entail custom code, retraining models, and a constant race against mark-up changes.
Many people have theorised that a language-centric AI engine could do a fine job at finding, understanding and extracting structured data directly from a given page source, without needing to rely on selectors. While the finding and understanding are straightforward, in generative AI, returning the identified content nevertheless consumes LLM output tokens, even though it was already contained in the supplied page mark-up. “Generating” the extraction of certain long attributes – like product descriptions or article bodies – with an LLM can burn through a lot of tokens, so the trick is to do so efficiently.
Data acquisition solutions need to scale to handle billions of records – so the quest was on to build a low-token method of extracting page content. We began by instructing an LLM to smartly extract text. For instance, if a certain product characteristic is contained within a long product description, our LLM engine does a fantastic job at extracting the property by generating the extracted value.
But, when the task requires larger text to be returned - let’s say, the whole product description itself or the complete body of a news article - we found LLMs to be costly and slow.
To tackle these cases, we have defined an internal HTML cleaning and annotation pre-processing strategy that, when coupled with the fine-tuning of the LLM, allows the system to extract data by asking the LLM to identify only the most relevant document nodes.
These node references use only two or three tokens, and function as signposts for guiding parsing of the target content from our original page source. The final value is precisely the relevant piece of HTML – but the LLM never had to use tokens to “generate” it at all.
Conjuring data from words
Then came the "aha!" moment – or rather, a series of small realizations.
In 2023, we started experimenting with LLMs for free-form data extraction of unpredictable and longer content from pages. Our first attempts were messy. The LLM would sometimes hallucinate or go off on irrelevant tangents. But there was something intriguing – a glimmer of genuine understanding.
We realised we could use natural language to describe exactly what we wanted to extract from a page, and the LLM, more often than not, would deliver.
The key insight was combining the power of LLMs with our existing, robust infrastructure. We didn't need to reinvent web scraping; we needed to give it a powerful new brain.
For those cases where the intended content could not be found, we developed a method to target specific HTML elements on the page. Think of it like this: instead of asking the LLM to rewrite an entire book, we asked it to first create a detailed table of contents, complete with page numbers. From there, our existing systems could quickly and efficiently retrieve the referenced content.
This approach dramatically reduced the number of tokens the LLM needed to process, making the process far more efficient, accurate, and cost-effective.
The result? Since January 2025, Zyte API’s AI Extraction has been smart enough to understand how to find complex combinations of non-standard on-page content.
Magic data on command
It starts with Zyte’s ability to understand users’ intent via natural-language scraping instructions.
Where, once, you needed to specify particular on-page selectors, now you can simply issue a command in written English.
Take a product page as an example. Typically, an ecommerce listing contains a single price, occasionally an additional discount price – something our standard product schema has long handled effortlessly. But what if you want to get three price points from the page?
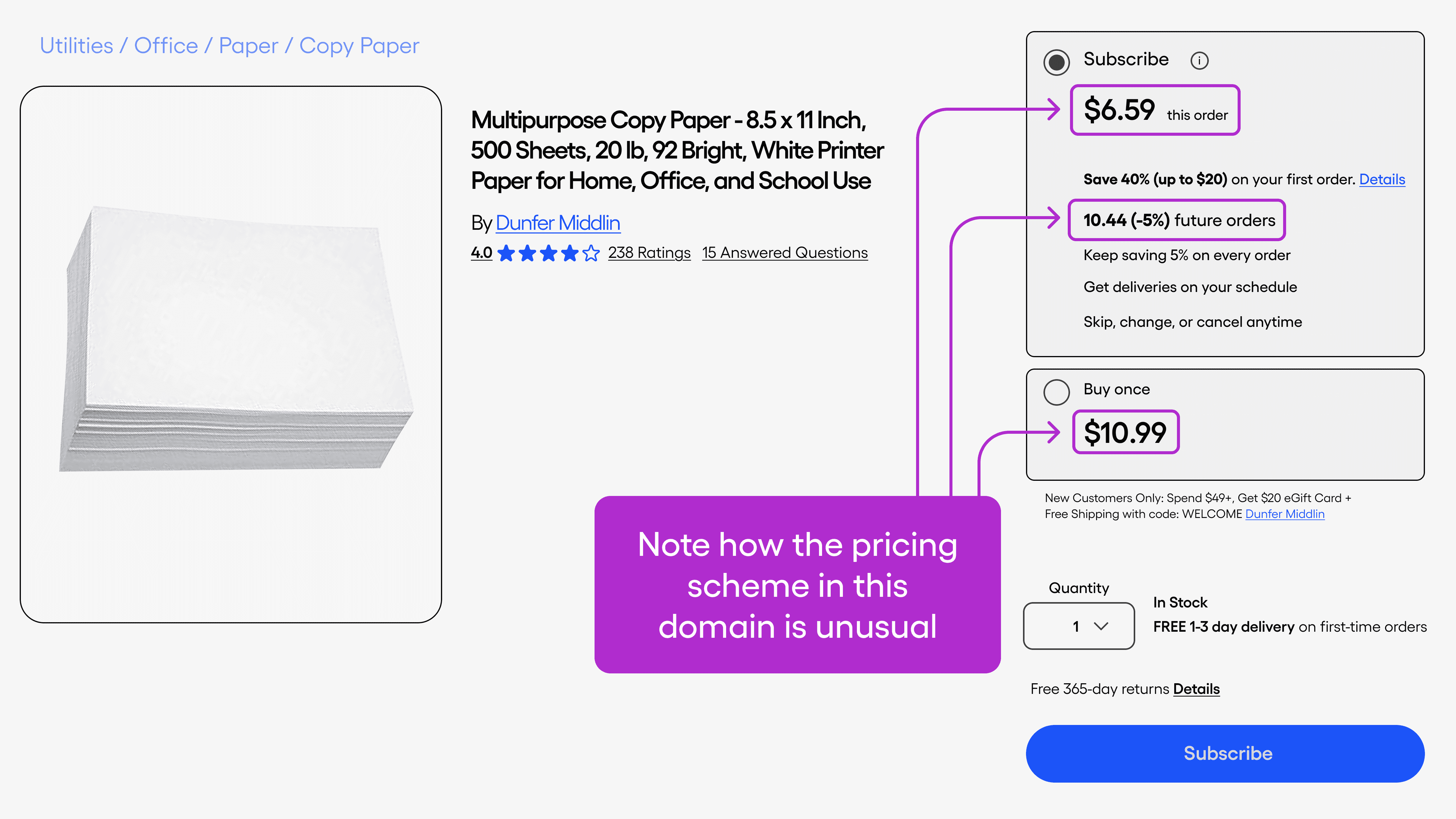
Automatic extraction using LLMs is now part of Zyte API’s AI Extraction feature, meaning your API call can issue direct instructions to get custom attributes specified with customAttributes:
1response = await client.get(
2 {
3 "url": url,
4 "browserHtml": True,
5 "product": True,
6 "productOptions": {
7 "extractFrom": "browserHtml",
8 },
9 "customAttributes": {
10 "price": {
11 "type": "object",
12 "description": "Analysis and values of the different pricing options to purchase the product",
13 "properties": {
14 "analysis": {
15 "type": "string",
16 "description": "Analyze all the different price options to purchase the product shown in the page."
17 },
18 "subscriptionPriceNow": {
19 "type": "number",
20 "description": "price for the product when bought through a subscription or special service, such as repeating deliveries. In particular, the price of the current purchase"
21 },
22 "subscriptionPriceFuture": {
23 "type": "number",
24 "description": "price for the product when bought through a subscription or special service, such as repeating deliveries. In particular, the price of future purchases"
25 },
26 "priceOneTimePurchase": {
27 "type": "number",
28 "description": "price for the product when bought through a one-time purchase."
29 }
30 }
31 }
32 }
33 }
34)Notice how the initial description primes the LLM with the overarching task it is being given, while the subsequent descriptions provide granular information designed to direct the engine toward specific on-page information.
The result is a combination of the actual on-page data and original text generated in line with the instruction:
1{
2 "values": {
3 "price": {
4 "analysis": "The product has multiple pricing options. The first time Autoship price is $6.59, which is a discounted price for the first order. The regular Autoship price is $10.44, which is a 5% discount from the one-time purchase price of $10.99.",
5 "subscriptionPriceNow": 6.59,
6 "subscriptionPriceRecurr": 10.44,
7 "priceOneTimePurchase": 10.99
8 }
9 },
10 "metadata": {
11 "inputTokens": 4639,
12 "outputTokens": 711,
13 "textInputTokens": 4375,
14 "textOutputTokens": 3221,
15 "maxInputTokens": 19354,
16 "maxOutputTokens": 19674,
17 "excludedPIIAttributes": []
18 }
19}To us, this feels like magic. But we call it “custom attribute extraction”, and it’s available now inside Scrapy Cloud and via Zyte API.
For a more detailed walkthrough on all of this, check out my code notebook and our docs for custom attribute extraction and Zyte API.
Why you should care
As technologists, the work we’re doing is incredibly satisfying to work on – but any software’s test of success is that it can solve real-world problems cost-effectively to be of any practical use.
Our customers extract data from many billions of pages every month. The enhancements mean they are now doing it faster and cheaper.
We should know. After all, we are our own largest customer. Zyte Data, our done-for-you data extraction service, uses Zyte’s own tools on customers’ behalf. We have seen first-hand how the LLM upgrades have powered-up our workflow.
A future fuelled by language
Zyte's journey is just one example of a larger trend. The ability to extract web data using natural language is poised to democratise access to information, making it easier for businesses, researchers, and individuals to gain insights from the web.
We're seeing this in the rise of other LLM-powered tools and libraries, and the increasing adoption of this approach across various industries. This shift has profound implications:
It lowers the barrier to entry for web scraping, enabling those without coding expertise to gather valuable data.
It increases agility, allowing for rapid adaptation to changing website structures and evolving data needs.
And it opens up new possibilities for data analysis, enabling us to ask more complex questions and uncover deeper insights.
However, challenges remain. While such a method can significantly reduce costs, LLM usage still involves computational expense. Meanwhile, the potential for bias in LLM output, as well as the need for thoughtful prompt design, requires careful monitoring.
The future of web data extraction is undoubtedly intertwined with the continued development of language models.
We are excited to be a part of this journey, constantly learning and adapting as we explore the boundless possibilities of natural language data extraction.