
A few years ago, I found myself at PyCon US during the twentieth anniversary of BeautifulSoup.
It was a fascinating session where people from all corners of the community stood up to share projects they had built using this incredible library. I was captivated by the sheer variety of applications. But more than that, I was struck by the intersection of this technical tool with real-world data and, by extension, with society itself.
That experience was my first deep introduction to the world of web scraping, and it set me on a path to understanding that this practice is never just a technical endeavor.
While I’m a QA Engineer by trade and don't professionally scrape data every day, my passion lies at the intersection of statistics, data, and society. I believe we can use data to better understand and improve the world. This belief has led me to explore web scraping not as a mere tool for data extraction, but as a social practice—an act that carries with it a host of decisions, considerations, ethical responsibilities, and necessary compromises.
In our data-hungry world, especially with the emergence of Large Language Models (LLMs) that scrape the web on a colossal scale, everyone is now a scraper, whether directly or indirectly. This makes it more crucial than ever to discuss how we can do it responsibly.
My journey into ethical scraping
The moment the social weight of scraping truly crystallized for me was during a personal project involving the Bracero History Archive. This is a historical digital archive containing over 3,000 oral history interviews with former Mexican guest workers who participated in the Bracero Program between 1942 and 1964.

Source: “braceros”, Oregon State University via Flickr (CC BY-SA 2.0)
My goal was to use scraping to collect this text data for analysis. But as I began, I realized I wasn't just downloading HTML; I was handling the stories, memories, and lived experiences of thousands of people. These were their voices, their hardships, and their histories.
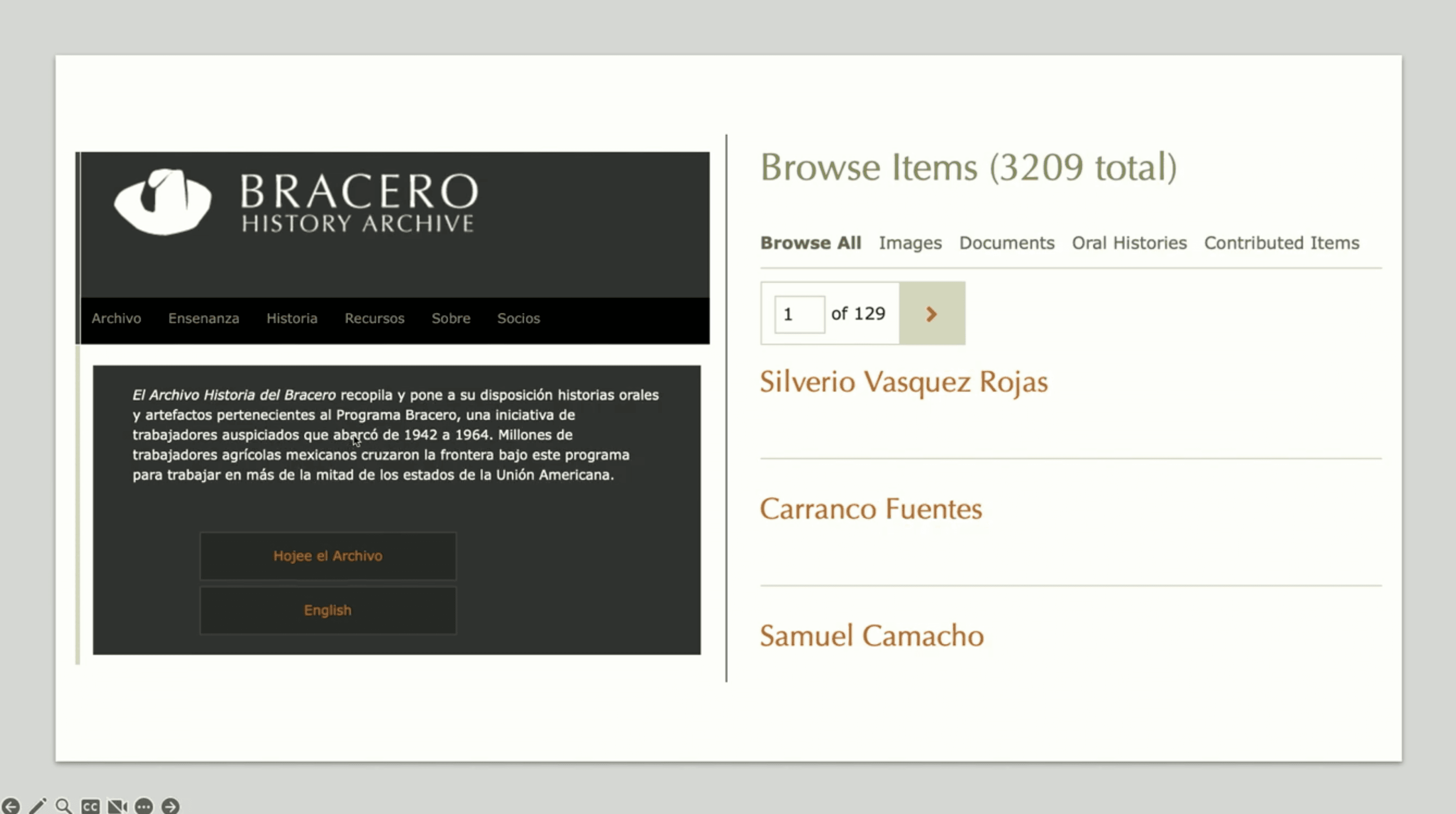
The task immediately transformed from a technical challenge into an ethical one. How could I ensure I was treating this data with the respect it deserved? How could I avoid misinterpreting or miscategorizing their stories due to a flaw in my code?

This project forced me to confront the reality that scraping is an act of negotiation. It involves balancing my goals as a data scientist with the legal, social, and infrastructural contracts of the web. It’s about more than just getting the data; it’s about how you get it and what you do with it.
The core questions: Who really controls the data?
This experience led me to a set of fundamental questions that I believe every scraper should ask themselves before writing a single line of code.
1. Public vs. proprietary: Who owns this data?
The first distinction is between public and proprietary data. While the lines can be blurry, this initial question sets the stage for our responsibilities.
2. If it’s public, is it truly “free” to take?
This is a common misconception. Just because data is publicly accessible, that does not mean it is free from context, legal, or ethical considerations. Public data, especially personal data or historical archives, comes with an implicit social contract. Ignoring this can lead to real-world consequences, from violating privacy to misrepresenting history.
3. Is scraping a conflict or a negotiation?
It's often framed as an adversarial relationship: the scraper versus the website. I believe it's more productive to view it as a negotiation. On one side are the goals of developers and data scientists who need data. On the other are the legal and social contracts of the web, along with the technical limitations of the server. A successful, ethical scrape is one that finds a healthy compromise between these competing factors.
4. How does context matter?
Context is everything. Your approach to scraping should change dramatically depending on your target. For example:
Government websites often contain vital public information but may run on older, less robust infrastructure.
Small NGOs might host valuable data but have extremely limited resources, making them vulnerable to aggressive scraping.
Large e-commerce retailers have sophisticated defenses and are more likely to view scraping in a commercial, competitive context.
Educational websites (like books.toscrape.com) are explicitly designed to be scraped and serve as excellent, safe playgrounds for learning.
Understanding the nature and limitations of your target is the first step toward responsible scraping.
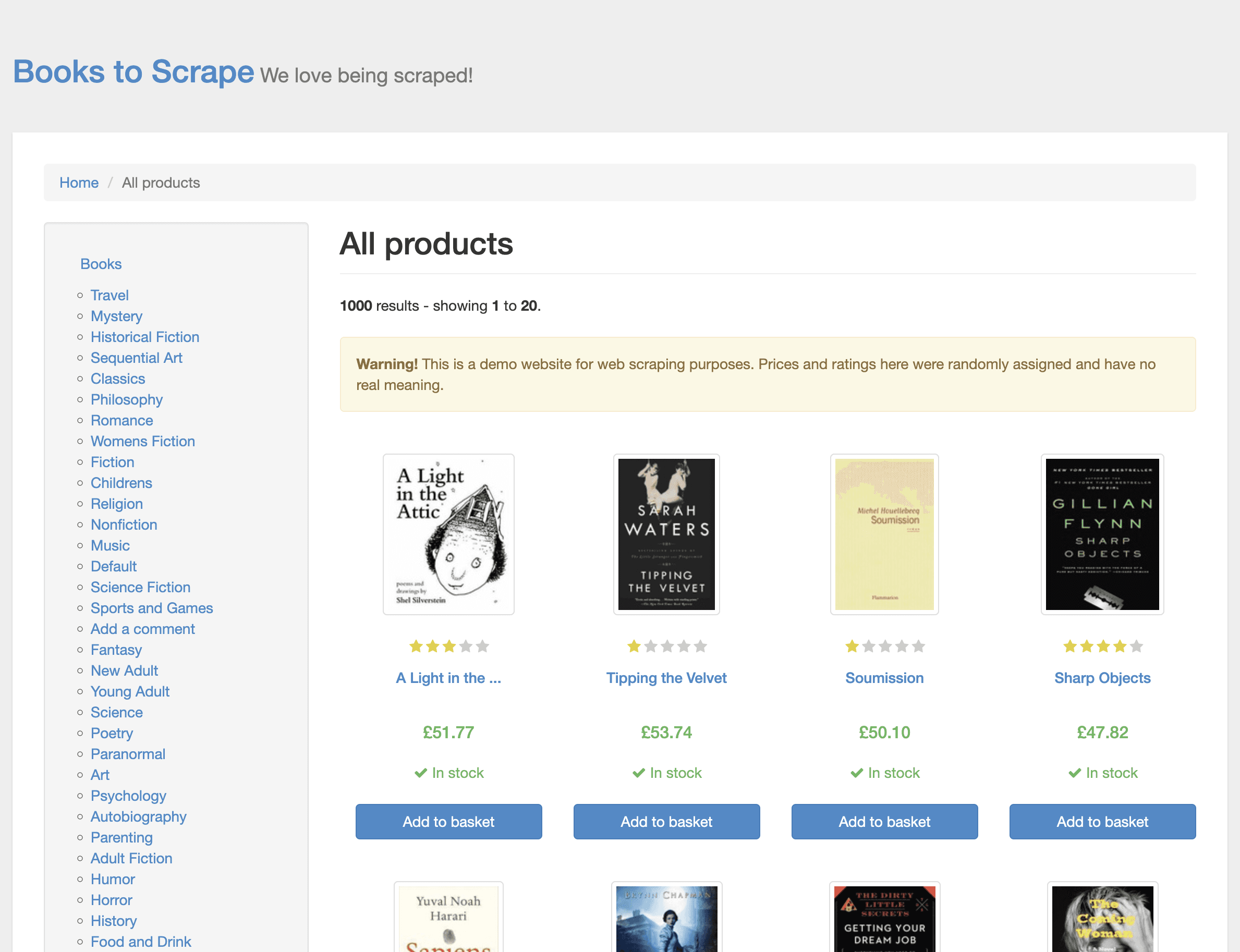
A framework for ethical and responsible scraping
Over time, I've developed a set of principles that guide my scraping projects. These are not just abstract ideas; they translate into concrete technical strategies.
1. Respect signals
If you are conducting a broad crawl that could place strain on the website, consider inspecting its robots.txt file first. With these files, publishers often provide guidance on their tolerance to crawling.
2. Respect infrastructure
Websites are not limitless resources. Implement rate limits and exponential backoff strategies in your code. The goal is to retrieve the data you need without hammering the server and degrading the service for other users.
3. Respect identity
Be honest. Don't impersonate or misrepresent your bot. While rotating user agents is a common practice to avoid being blocked, do it responsibly. Identify your bot as a crawler where possible and don’t claim to be a browser you’re not.
4. Respect data subjects
This is especially critical when dealing with sensitive or personal information. Collect the minimum necessary data. Do you have a lawful basis for storing this information? Consider aggregation or anonymization to protect individuals.
Practical technical strategies for the mindful scraper
These ethical principles can be implemented through several practical technical strategies. Here are a few key ones I've found useful.
Choose the right tools
Python offers a fantastic ecosystem.
Requests: A simple, elegant library for making HTTP requests.
BeautifulSoup: My first love in the scraping world. It’s brilliant for parsing HTML and XML documents.
Scrapy: A powerful, full-fledged framework for building complex and scalable web crawlers.
Adopt an efficient workflow
To minimize your impact on the server, follow this mantra: retrieve once, analyze locally.
Instead of repeatedly hitting a website every time you tweak your parsing logic, retrieve the raw HTML pages first.
Cache these requests locally. This creates a static version of the site on your machine that you can analyze and re-analyze as much as you need without ever sending another request to the server.
Reduce server strain:
Parallelization with care: While it’s tempting to speed things up with parallel requests, this can easily overwhelm a server. Use concurrency carefully and always in combination with throttling.
Throttling requests: Intentionally slow down your scraper. Introduce delays between requests to reduce load on the server.
APIs vs. scraping: Know when to choose
Before you scrape, always check if a public API is available. An API is the website's sanctioned way of providing data. There are important trade-offs to consider:
APIs are generally more stable and efficient but may be rate-limited or provide incomplete data.
Scraping is more flexible and can access anything on a page, but it is heavier, more brittle (breaks when a site’s layout changes), and carries more ethical overhead.
A perfect example of this is Wikipedia. Countless tutorials teach you how to scrape it, but this is almost always the wrong approach. The Wikimedia Foundation provides a robust API for a reason. Please, do not scrape Wikipedia! Use their API. It respects their infrastructure and is the more responsible choice.
Scraping is never just technical
Scraping is a discipline that requires more than just technical skill. It requires thoughtful decisions, careful considerations, an awareness of context, and a willingness to make compromises.
I am currently applying these ideas to a new project: text-mining the community names from the now-defunct social media site Orkut, using archives from the Wayback Machine.

It's a fascinating challenge in digging into our collective "digital memory," and it comes with its own unique set of ethical questions.
As data becomes ever more central to our world, the way we collect it matters. By approaching web scraping as a social practice, we can balance the drive for efficiency with a deep-seated respect for the digital ecosystem and the people within it. In doing so, we can use our technical skills not just to gather data, but to contribute positively to building a better world.
Rodrigo Silva Ferreira is QA Engineer, Posit