
Insurance & credit scoring with alternative data
Why bureau data is not enough to score consumers
Whether we are talking about the credit-granting or insurance underwriting arena, alternative data usually refers to datasets not inherently related to an individual's credit or insurance claim behavior. Traditional data is usually circumscribed to that originating at a credit bureau (think Equifax. Experian, TransUnion), credit or insurance application data, or an institution's proprietary files on an existing customer.
Alternative data has a lot of senses become not only a hot topic but even a buzzword, partly because of the data explosion of the last decade (IDC estimated that in 2010 1.2 zettabytes of data were created that year. 2018 saw 33 zettabytes of data made, leading IDC to predict that in 2025, 175 zettabytes of new data will be produced worldwide). And partly because of the hype that it has received from bullish hedge funds and other organizations that tend to be more prone to experiment with 'new' approaches. Full-time employees dedicated to leveraging alternative data in this space have grown by 450% in the last five years, with 44% of funds now having dedicated teams to reap the benefits of this data alt. data onslaught, according to EY.
But the other side of the coin is that there are an estimated 3 billion adults around the globe with no credit, therefore no credit files whatsoever, according to the scoring leader FICO. It is a vast under-serviced market in many parts of the world. While many of these adults live in developing and frontier markets with early-stage credit infrastructures, it is also true that there are large amounts of people in mature markets that have no credit files, thereby unknown to the credit bureaus. These are the so-called 'credit invisibles'.
Why being 'credit invisible' matters, one may ask? In the US, for example, one if not the most significant and most mature credit & insurance market, according to the Consumer Financial Protection Bureau 'consumers with limited credit histories reflected in the credit records maintained by the three nationwide credit reporting agencies (NCRAs) face significant challenges in accessing most credit or insurance. NCRA records are often used by lenders when making credit and/or insurance underwriting decisions. In reality, lenders and insurers often use a scoring solution, such as one of the FICO or VantageScore scores derived from NCRA records when deciding whether to approve a loan application or in setting a loan’s interest rate. If an applicant does not have a credit record with one of the NCRAs or if the record contains insufficient information to assess her creditworthiness, lenders & insurance companies are much less likely to extend credit facilities or indeed take onboard the individual part of an insurance scheme. As a result, consumers with limited credit & claim histories can face substantially reduced access to these markets.'
There are an estimated 53 million people with either insufficient credit bureau files (28million) or non-existent records on the bureaus altogether (25 million) in the US. Minimum scoring criteria as publicly explained by some of the market leaders in this space are:
- The consumer cannot be deceased
- Credit file needs at least one account reported within the last six months
- Credit file needs at least one account that is at least six months old
FICO recently completed research on how to potentially extend credit to 'unscorable' consumers, those that do not fit the standard criteria set above. FICO analyzed 28 million consumers that only had sparse or stale credit bureau data. TL;DR version - is it impossible! As the research showed that creating scoring models solely based on old or lackustre credit data did a poor job forecasting future performance.
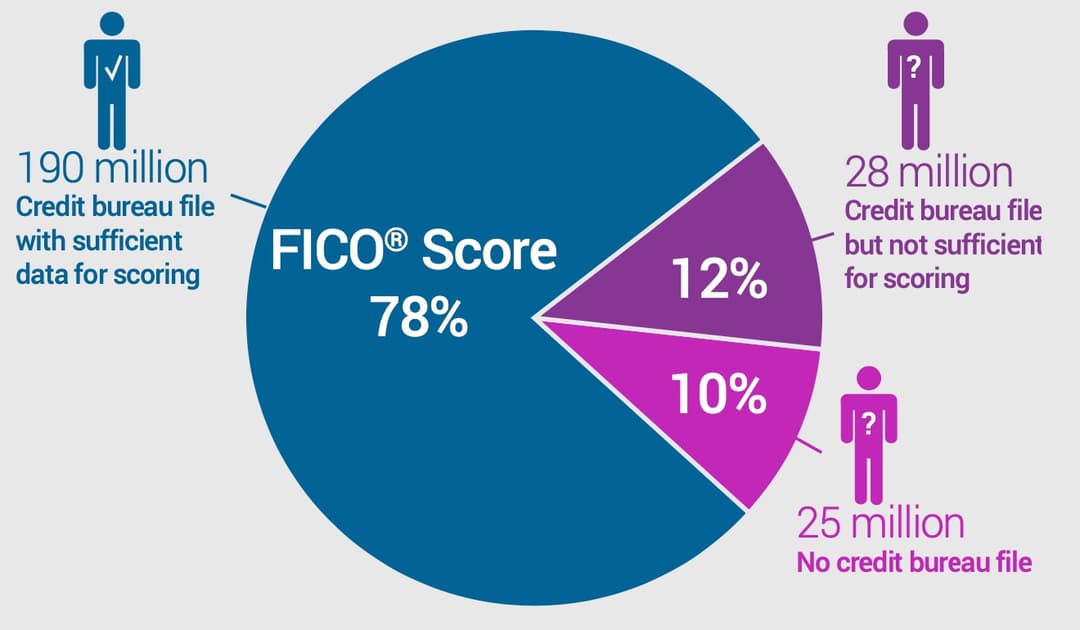
The research developed a score of roughly 7 million consumers with at least some public records available. The results show that the older the data, the less reliable the scoring model becomes. The inherent risk level associated with any particular score, say 650, will not be the same across successive segments of the population with stale records.
Why is this a problem? Think about mortgages. Lenders that are coming up with an underwriting strategy at a given score cutoff could actually be taking on customers with decidedly different repayment risk, although they all have the same score of 650. This situation arises, as previously explained, because the underlying scoring model performance is less reliable the older the data used to score the consumer is in the first place. FICO actually showed that “ a 640 score based on files that have not been updated in 21 months or more exhibits repayment risk roughly in line with a 590 score for the traditionally scorable population—an odds misalignment of about 50 points.”
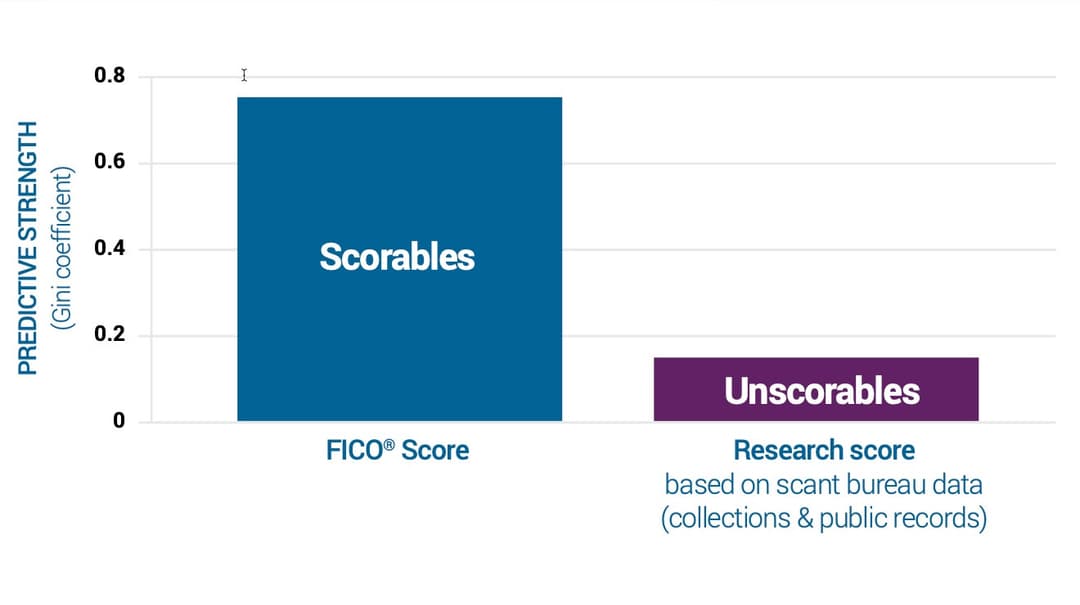
The bottom line is that risk discrimination is weak when scoring on sparse or old bureau data. Lenders using weak scores would mean they will likely decline clients they should have accepted and vice-versa. For consumers, it translates to possibly receiving smaller credit lines (if at all) than requested or, worse, higher than they can actually afford.
Furthermore, for the vast majority of these 28 million consumers, traditional data-based scoring models would not make it at all easy for them to get access to credit in the first place. More than half are reported by at least one of the big three NCRAs to have a negative item or no active account from which to derive information. Without data flowing into the scoring model for it to be positively influenced, they are less likely to access credit. They are effectively locked up in a vicious cycle: To obtain credit or insurance, they need to be using credit or insurance facilities – but without a reliable way to assess their risk, lenders and insurers are probably not going to take the chance to take them on as clients.
For the 25 million-odd remaining potential consumers in the US market, with no files at all, bureau data will not help either. They are also caught in this catch-22 scenario.
Therefore, if credit or insurance is indeed going to be provided to this sizable 'unscorable' audience, credit bureau data must be appended by non-traditional forms of data.
Now that we know the why of the need to leverage alternative data let's address the elephant in the room from the word 'go'.
Alternative data isn't reduced to social media sourced data. As a matter of fact, there are self-evident reasons why data sourced from Facebook, Instagram, Twitter, etc., doesn't exactly scream quality data for the purposes of credit/insurance risk scoring.
So if alternative data is not just social media sourced data, what is it?
Multiple types of alternative data
-Transaction data 💵
This type of data is typically defined as consumer usage patterns of credit and debit cards. One may ask, how is transaction data 'alternative'? A lot of this data is not actively mined to build predictive models.
Drawback - Time intensive
Positive - Data is generally very well structured and clean
-Utility/Rental data🔌🏡
It is generally historical data, but seldomly does it appear in the reports from the main NCRAs. Some scoring companies have actually included it as part of their product offerings, mainly for the US market.
-Clickstream data🌐
In layman's terms, this is how users navigate through websites. With the 'death' of third-party cookie tracking in most, if not all browsers by 2022, and last years' news that Avast was starting to wind down its subsidiary Jumpshot, this type of data has become more scarce and dare I say more unreliable.
-Audio & text Files 🔊📚
This type of unstructured data is usually sourced from credit/insurance application documents, call recording between customer and the lender, etc.
-Social network analysis🕸️
With the technology that underpins knowledge graphs becoming more and more mature over the last couple of years, this approach to analysis relationships amongst seemingly disparate datasets can serve as the digital substrate to unify the philosophy of knowledge acquisition and organization within the master data management discipline in the digital age. And ontologies, the elaborate schemas that govern knowledge graphs, are now being used by the Morgan Stanleys of the world.
_-Survey / Questionnaire dat_a ⁉️
Companies such as LenddoEFL are using psychometrics, a field of study concerned with the theory and technique of psychological measurement, to mine these datasets into mathematical predictive scoring solutions.
-Web data 🔗
This is where Zyte shines. This type of data can be anything that is part of a public online repository, be it forum posts on a particular topic, product & pricing information, product & service reviews, etc. Global accounting firm EY has actually called out web data as the second most precise & insightful alternative dataset.
-Geolocation data 🗺️📍
Geolocation data is information that can be used to identify an electronic device's physical location. With users basically taking their connected devices with them everywhere, it has become a growing data source to assess anything from store footfall to traveling patterns of populations.
How much value is there in the data?
Recent research has shown that the above-mentioned data sources do, in fact, add predictive value to credit and org insurance risk models that are fundamentally based on traditional data. While the amount of predictive value bestowed upon the underlying model is dependent on underlying variables such as the strength of the customer relationship with the lender, the original predictive performance of the traditional data-based model, the overall performance gains per data set are somewhere in the region of 5% -20%. For example, social network data is generally much more valuable when applying it to new customer onboarding scenarios (~10%-20% model performance gain) than when there is already a strong relationship between the parties (5%-15%). In this hypothetical scenario, transaction data is another very strong predictor.

The below chart shows the results of one project undertaken by FICO, one of the leading scoring solution providers, on a personal loan portfolio. "The traditional credit characteristics captured more value than the alternative data characteristics (with the alternative data capturing about 60% of the predictive power), and there was a high degree of overlap between the two." That said, when the two datasets were combined, the overall model performance improved significantly.

How can alternative data be productized? Where does AI & machine learning fit into the picture
Leveraging alternative data effectively while extremely powerful, as I have shown above, does not come without its challenges. Various analytic technologies and machine learning approaches are implemented to deal with the large unstructured data sets. Identifying patterns in the data that can be effectively and efficiently used in credit and/or insurance risk scenarios is challenging.
Notwithstanding, the key element in the application of machine learning and AI continues to be the data scientists. Models need to undergo stringent quality assurance processes to guarantee the accuracy of the output, that the patterns identified are strong, relevant, and explainable. And it is this last element that, going forward, raises the biggest eyebrows and concerns. How can AI-driven alternative data-empowered scoring models be explained to both consumers and regulatory authorities.
A very concrete example where model explainability interacts with the regulatory and compliance domain is within the context of the General Data Protection Regulation (GDPR).
Article 22 of the GDPR relates to “Automated individual decision-making, including profiling”. Processing is automated when it is carried out without human intervention. Under Article 22 an individual has the right not to be subject to a decision based solely on automated processing including profiling, which produces legal effects concerning for, or, similarly significantly affects the individual. The GDPR cites the “automatic refusal of an online credit application” as a typical example of automated decision-making producing legal or similarly significant effects.
Automated processing is permitted in certain circumstances under GDPR but only when there are suitable measures in place to safeguard an individual’s rights including allowing an individual a way to request human intervention, express a point of view and challenge a decision.
This is where it gets complicated for AI-powered scoring_._ AI, in general, does not have a 'black-box' reputation for nothing; therefore, in risk applications, customers need to have clear-cut reasons as to why they have been adversely impacted by a decision. Where the decision is model-based, the model needs to be explainable to the point where the individual drivers of negative and positive scores are clear. If this is a simple traditional scorecard, then the explanation is self-evident. But troubles begin when the AI model is not as clear cut, raising the bar yet again for AI explainability (Scott Zoldi from FICO and Trent McConaghy from Ocean Protocol have some interesting articles on the topic).
Where does this leave us?
In order to satisfy the demands of the market, both from lenders and insurers looking to attract new customers and from the point of view of consumers, a risk scoring strategy that incorporates alternative data sources is paramount.
While the above may well be underway with the likes of FICO & VantageScore coming to the market with some level of alternative data enhanced scores, what is clear is that the appetite to source alternative data; web data in particular, is only growing. It is therefore blatantly obvious that scoring companies, lenders and insurers need to invest in a resilient alternative data harvesting infrastructure and process.
Keeping a watchful eye on AI explainability is also paramount, so as to remain compliant with current regulatory requirements and also providing a fair degree of transparency to consumers.
FAQs
Why is traditional credit bureau data insufficient for scoring consumers?
It fails to include over 3 billion "credit invisible" adults worldwide and lacks predictive strength for stale or sparse records.
What is alternative data in the context of credit and insurance scoring?
Alternative data includes non-traditional datasets such as transaction patterns, utility payments, clickstream data, geolocation, and more.
How does alternative data improve predictive models?
Combining traditional and alternative data enhances model performance by 5%-20%, providing better risk assessment and accessibility.
Why is AI explainability important in alternative data scoring?
Transparent AI models are necessary to meet GDPR requirements and build trust with consumers by clearly explaining decision-making processes.
What is the potential impact of alternative data on underserved consumers?
It expands credit and insurance access to unscorable consumers, enabling fairer opportunities for financial inclusion.





_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
