
Link analysis algorithms explained
When scraping content from the web, you often crawl websites which you have no prior knowledge of. Link analysis algorithms are incredibly useful in these scenarios to guide the crawler to relevant pages.
This post aims to provide a lightweight introduction to page ranking algorithms so you have a better understanding of how to implement and use them in your spiders. There will be a follow up post soon detailing how to use these algorithms in your crawl.
PageRank
PageRank is perhaps the most well known page ranking algorithm. The PageRank algorithm uses the link structure of the web to calculate a score. This score provides insight into how relevant the page is and in our case can be used to guide the crawler. Many search engines use this score to influence search results.
One possible way of coming up with PageRank is by modelling the surfing behavior of a user on the web graph. Imagine that at a given instant of time [LaTeX formula] the surfer, [LaTeX formula], is on page [LaTeX formula]. We denote this event as [LaTeX formula]. Page [LaTeX formula] has [LaTeX formula] outgoing and [LaTeX formula] incoming links as depicted in the figure.
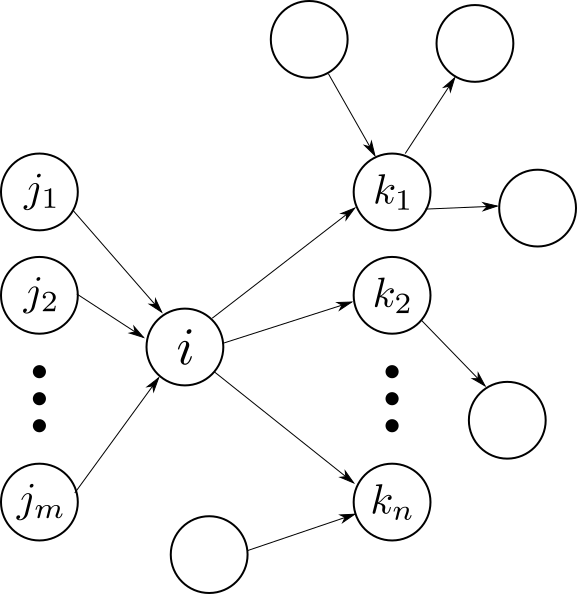
While on page [LaTeX formula] the algorithm can do one of the following to continue navigating:
- With probability
[LaTeX formula]follow randomly an outgoing link. - With probability
[LaTeX formula]select randomly an arbitrary page on the web. When this happens we say the the surfer has teleported to another page.
So what happens if a page has no outgoing links? It's reasonable to assume the user won't stick around, so it's assumed that the user will 'teleport', meaning they will visit another page through different means such as entering the address manually.
Now that we have a model of the user behavior let's calculate [LaTeX formula]: the probability of being at page [LaTeX formula] at time instant [LaTeX formula]. The total number of pages is [LaTeX formula].
[LaTeX formula]
Now, the probability of going from page [LaTeX formula] to page [LaTeX formula] is different depending on wether or not [LaTeX formula] links to [LaTeX formula] ([LaTeX formula]) or not ([LaTeX formula]).
If [LaTeX formula] then:
[LaTeX formula]
If [LaTeX formula] but [LaTeX formula] then the only possibility is that the user chooses to teleport and it lands on page [LaTeX formula].
[LaTeX formula]
If [LaTeX formula] and [LaTeX formula] then the only possibility is that the user teleports to page [LaTeX formula].
[LaTeX formula]
We have assumed uniform probabilities in two cases:
- When following outgoing links we assume all links have equal probability of being visited.
- When teleporting to another page we assume all pages have equal probability of being visited.
In the next section we'll remove this second assumption about teleporting in order to calculate personalized PageRank.
Using the formulas above, with some manipulation we obtain:
[LaTeX formula]
Finally, for convenience let's call [LaTeX formula]:
[LaTeX formula]
PageRank is defined as the limit of the above sequence:
[LaTeX formula]
In practice, however, PageRank is computed by iterating the above formula a finite number of times: either a fixed number or until changes in the PageRank score are low enough.
If we look at the formula for [LaTeX formula] we see that the PageRank of a page has two parts. One part depends on how many pages are linking to the page but the other part is distributed equally to all pages. This means that all pages are going to get at least:
[LaTeX formula]
This gives an oportunity to link spammers to artificially increase the PageRank of any page they want by maintaing link farms, which are huge amounts of pages controlled by the spammer.
As PageRank will give all pages a minimum score, all of these pages will have some PageRank that can be redirected to the page the spammer wants to rise in search results.
Spammers will try to build backlinks to their pages by linking to their sites on pages they don't own. This is most common on blog comments and forums where content is accepted from users.
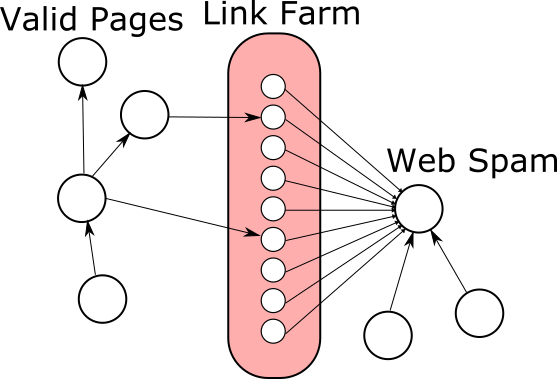
Trying to detect web spam is a never-ending war between search engines and spammers. To help filter out spam we can use Personalized PageRank which works by not assigning a free score to undeserving pages.
Personalized PageRank
Personalized PageRank is obtained very similar to PageRank but instead of a uniform teleporting probability, each page has its own probability [LaTeX formula] of being teleported to irrespective of the originating page:
[LaTeX formula]
The update equations are therefore:[LaTeX formula]
Of course it must be that:
[LaTeX formula]
As you can see plain PageRank is just a special case where [LaTeX formula].
There are several ways the score [LaTeX formula] can be calculated. For example, it could be computed using some text classification algorithm on the page content. Alternatively, it could be set to 1 for some set of seeds pages and 0 for the rest of pages, in which case we get TrustRank.
Of course, there are ways to defeat this algorithm:
- Good pages can link to spam pages.
- Spam pages could manage to get good scores, for example, adding certain keywords to its content (content spamming).
- Link farms can be improved by duplicating good pages but altering their links. An example would be mirrors of Wikipedia which add links to spam pages.
HITS
HITS (hyperlink-induced topic search) is another link analysis algorithm that assigns two scores: hub score and authority score. A page’s hub score is influenced by the authority scores of the pages linking to it, and vice versa. Twitter makes use of HITS to suggest users to follow.
The idea is to compute for each page a pair of numbers called the hub and authority scores. A page is considered a hub when it points to lot of pages with high authority, and page has high authority if it's pointed to by many hubs.
The following graph shows one several pages with one clear hub [LaTeX formula] and two clear authorities [LaTeX formula] and [LaTeX formula].
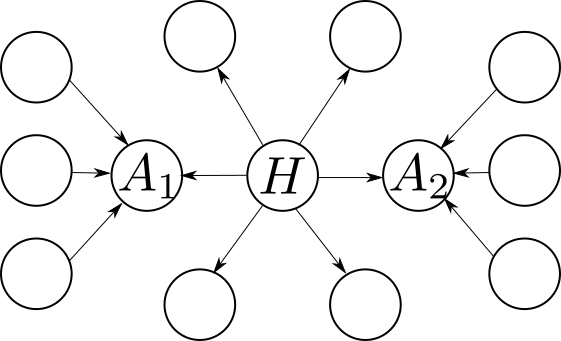
Mathematically this is expressed as:
[LaTeX formula][LaTeX formula]
Where [LaTeX formula] represents the hub score of page [LaTeX formula] and [LaTeX formula] represents its authority score.
Similar to PageRank, these equations are solved iteratively until they converge to the required precision. HITS was conceived as a ranking algorithm for user queries where the set of pages that were not relevant to the query were filtered out before computing HITS scores.
For the purposes of our crawler we make a compromise: authority scores are modulated with the topic specific score [LaTeX formula] to give the following modified equations:
[LaTeX formula][LaTeX formula]
As we can see totally irrelevant pages ([LaTeX formula]) don't contribute back authority.
HITS is slightly more expensive to run than PageRank because it has to maintains two sets of scores and also propagates scores twice. However, it's particularly useful for crawling as it propagates scores back to the parent pages, providing a more accurate prediction of the strength of a link.
Further reading:
- HITS: Kleinberg, Jon M. "Authoritative sources in a hyperlinked environment." Journal of the ACM (JACM) 46.5 (1999): 604-632.
- PageRank and Personalized Pagerank: Page, Lawrence, et al. "The PageRank citation ranking: Bringing order to the web." (1999).
- TrustRank: Gyöngyi, Zoltán, Hector Garcia-Molina, and Jan Pedersen. "Combating web spam with trustrank." Proceedings of the Thirtieth international conference on Very large data bases-Volume 30. VLDB Endowment, 2004.
We hope this post has served as a good introduction to page ranking algorithms and their usefulness in web scraping projects. Stay tuned for our next post where we'll show you how to use these algorithms in your Scrapy projects!







_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
