
Scrapely: The brains behind Portia spider
Note: Portia is no longer available for new users. It has been disabled for all the new organizations from August 20, 2018, onward.
Unlike Portia labiata, the hunting spider that feeds on other spiders, our Portia spider feeds on data. Considered the Einstein in the spider world, we modeled our own creation after the intelligence and visual abilities of its arachnid namesake.

Portia is our visual web scraping tool that is pushing the boundaries of automated data extraction. Portia spider is completely open-source and we welcome all contributors who are interested in collaborating. Now is the perfect time since we’re on the beta launch of Portia 2.0, so please jump in!

You don't need a programming background to use Portia. Its web-based UI means you can choose the data you want by clicking (annotating) elements on a webpage, as shown below. Doing this creates a sample which Portia later uses to extract information from similar pages.
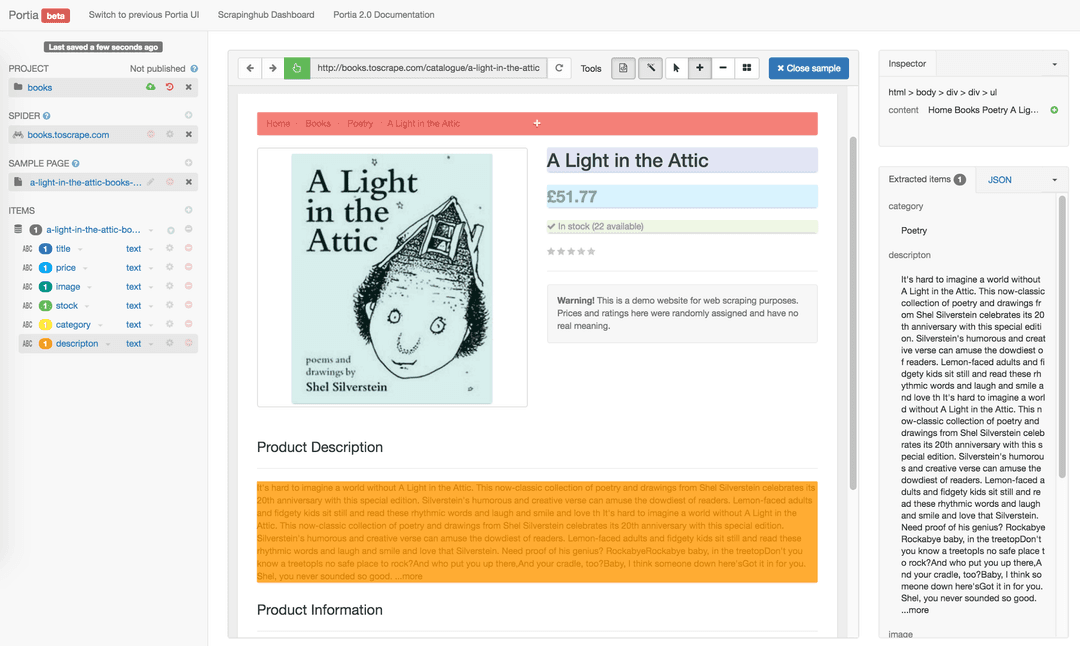
When taking a look at the brains of Portia, the first component you need to meet is Scrapely.
What is Scrapely?
Portia uses Scrapely to extract structured data from HTML pages. While other commonly used libraries like Parsel (Scrapy's Selector) and Beautiful Soup use CSS and XPath selectors, Scrapely takes annotated HTML samples as input.
Other libraries work by building a DOM tree based on the HTML source. They then use the given CSS or XPath selectors to find matches in that tree. Scrapely, however, treats an HTML page as a stream of tokens. By building a representation of the page this way, Portia is able to handle any type of HTML no matter how badly formatted.
Machine Learning Data Extraction
To extract data, Portia employs machine learning using the instance-based wrapper induction extraction method implemented by Scrapely. This is an example of supervised learning. You annotate an HTML page to create a set of pre-trained samples that guide the information extraction.
Scrapely reads the streams of tokens from the unannotated pages and looks for regions similar to the sample’s annotations. To decide what should be extracted from new pages, it notes the tags that occur before and after the annotated regions, referred to as the prefix and suffix respectively.
This approach is handy as you don’t need a well-defined HTML page. It instead relies on the order of tags on a page. Another useful feature of this approach is that Scrapely doesn't need to find a 100% match, and instead looks for the best match. Even if the page is updated and tags are changed, Scrapely can still extract the data.
More importantly, Scrapely will not extract the information if the match isn't similar enough. This approach helps to reduce false positives.
Portia + Scrapely
Now that you better understand the inner workings of Portia, let’s move to the front-facing portion.
When you click elements on a page, Portia highlights them. You can give each field a name and choose how they’re extracted. Portia also provides a live preview of what data will be extracted as you annotate.
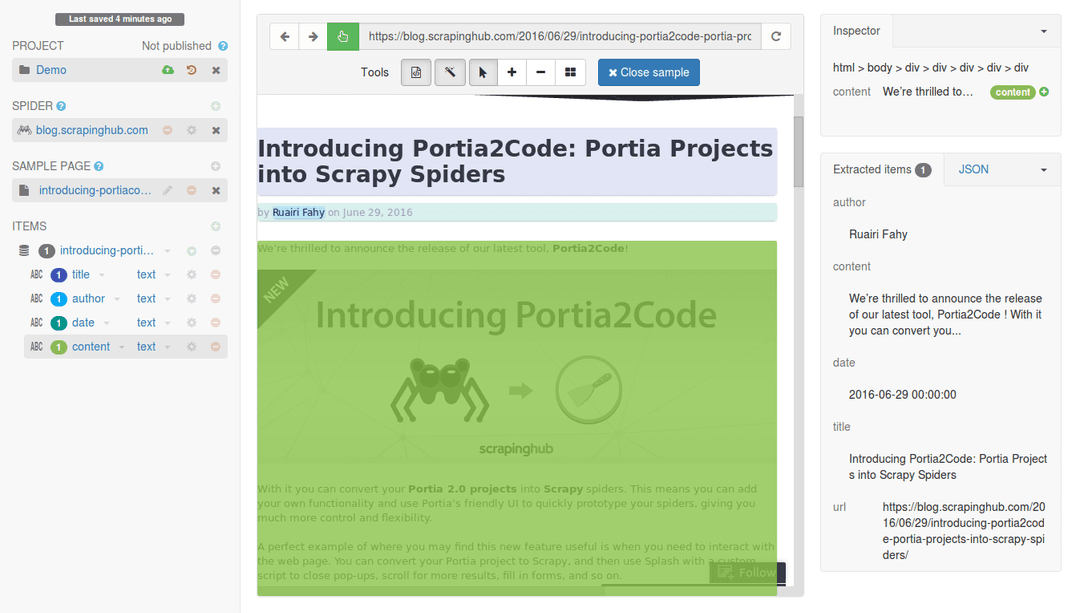
Portia passes these annotations to Scrapely, which generates a new HTML page that includes the annotations. You can see the annotated page’s HTML in the screenshot below:
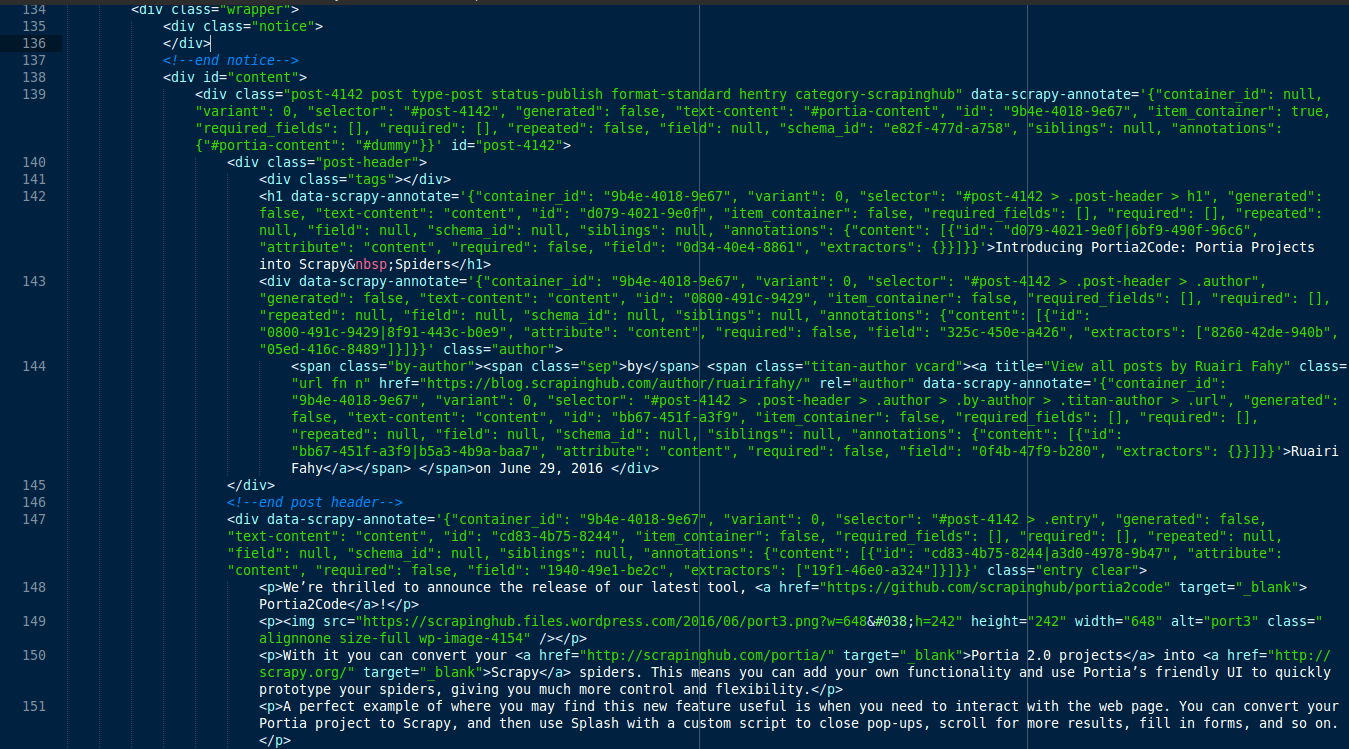
Scrapely then compiles this information into an extraction tree, which looks like this:
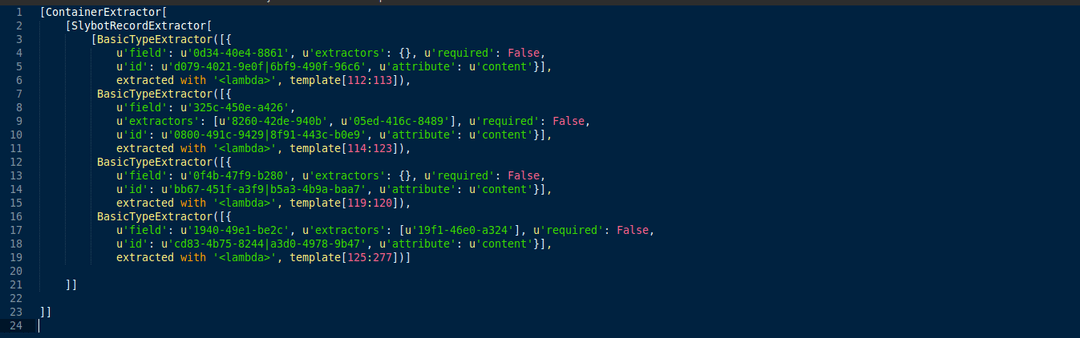
Scrapely uses the extraction tree to extract data from the page.
The ContainerExtractor finds the most likely HTML element that contains all the annotations.
Next, the RecordExtractor looks through this element and applies each of the BasicTypeExtractors from the tree, one for each field that you defined.
After trying to match all extractors, Scrapely outputs either an item with the data extracted or nothing if it couldn't match any elements that are similar enough to the annotations.
This is how Scrapely works in the background to support the straightforward UI of Portia.
The Future of Data Extraction
You currently need to manually annotate pages with Portia. However, we are developing technologies that will do this for you. Our first tool, the automatic item list extractor, finds list data on a page and automatically annotates the important information contained within.
Another feature we’ve begun working on will let you automatically extract data from commonly found pages such as product, contact, and article pages. It uses samples created by Portia users (and our team) to build models so frequently extracted information will be automatically annotated.
Wrap Up
And that’s Portia in a nutshell! Or at least the machine learning brains… In any case, I hope that you found this an informative peek into the underbelly of our visual web scraping tool. We again invite you to contribute to Portia 2.0 beta since it’s completely open-source.
Let us know what else you’d like to learn about how Portia works or our advances in automated data extraction.
Note: Portia is no longer available for new users. It has been disabled for all the new organizations from August 20, 2018, onward.







_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
