I recently had the pleasure of participating in the third episode of Graphversation, a monthly live stream series that brings together graph experts and Neo4j enthusiasts for engaging and enlightening discussions about the captivating world of graphs.
During this episode, I had the opportunity to talk with Siddhant Agarwal (APAC Developer Relations Neo4J) to share my perspective on recommendation engines, viewing them through the lens of systems thinking.
In the webinar I explore how we can significantly enhance the personalization and discoverability of recommendation engines by focusing on two of its crucial elements - the web scraping or data collection phase, and the incorporation of data into graph databases.
What you will learn if you watch:
You'll gain an understanding of how recommendation engines work, with a focus on the crucial aspects of web scraping for data collection and the use of graph databases.
Learn key terms and concepts in systems thinking and their application in the context of recommendation engines.
Discover the role of specific tools, such as the Zyte API for effective web scraping, and graph databases like Neo4j for efficient data representation and management.
If you want to watch the episode on demand, you can watch Graphversation Ep. 3 How Web Scraping and Graph Databases Power Recommendation Engines.
In this blog, I will walk you through the process of supercharging your recommendation engines and integrating web data with graph databases. We'll delve into how these elements can be manipulated and optimized to create a more personalized, efficient, and effective recommendation system.
Systems Thinking - Key Terms
Systems thinking involves viewing a system as a cohesive whole, rather than just a collection of individual parts. It’s about understanding how different parts of a system, like a recommendation engine, interact and impact each other. In our example, user profiles, viewing histories, ratings, content databases, and algorithms all form a system within the recommendation engine. When one part changes, such as an algorithm update to prioritize new content, it can affect the entire system, altering user recommendations, affecting ratings, and potentially impacting user satisfaction. By using a systems thinking approach, we consider these interdependencies, anticipate consequences, and make balanced decisions that improve the system as a whole.
I came across this concept in the book Thinking in Systems by Donella Meadows. But for some quick basics, you can also read this article concept- Tools for Systems Thinkers: The 6 Fundamental Concepts of Systems Thinking by Leyla Acaroglu.
To align our understanding of systems thinking, let's look at some key terms:
Elements: These are the tangible and intangible components that work together within a system. In the context of a recommendation engine, elements could be users, items to be recommended (like books or movies), and the interactions between users and items.
Interconnections: These describe the relationships within the system between the elements. These relationships could be user-item interactions, similarities between items, or similarities between users.
Purpose/Goal/Function: This is the overall objective or goal of the system. For a recommendation engine, the purpose could be to increase user engagement, improve sales, or enhance user satisfaction through personalization.
Feedback Loop: This is the mechanism through which the system learns and adapts. In a recommendation engine, a feedback loop could be the process of using user feedback to update the recommendations.
The Power of Graphs: A Representation of Systems Thinking
Graphs are powerful tools that can represent systems thinking effectively. They are everywhere and provide a better and closer representation of the world around us. Therefore, problems can be better visualized with graphs unless we find a better data structure to represent the data.
In terms of graph theory:
Node: Represents an element in the system. In the context of a recommendation engine, a node could represent a user or an item (like a book or a movie).
Edge: Represents the relationship or interconnection between nodes. In a recommendation engine, an edge could represent the interaction between a user and an item.
By representing elements as nodes and interconnections as edges, graphs can effectively model the relationships and interactions within a system. This makes them particularly useful for systems thinking, as they allow us to visualize and understand the complex interplay of elements within a system. For instance, in a book recommendation system, a graph database could help us understand the relationships between users and books, and use this understanding to make better recommendations.
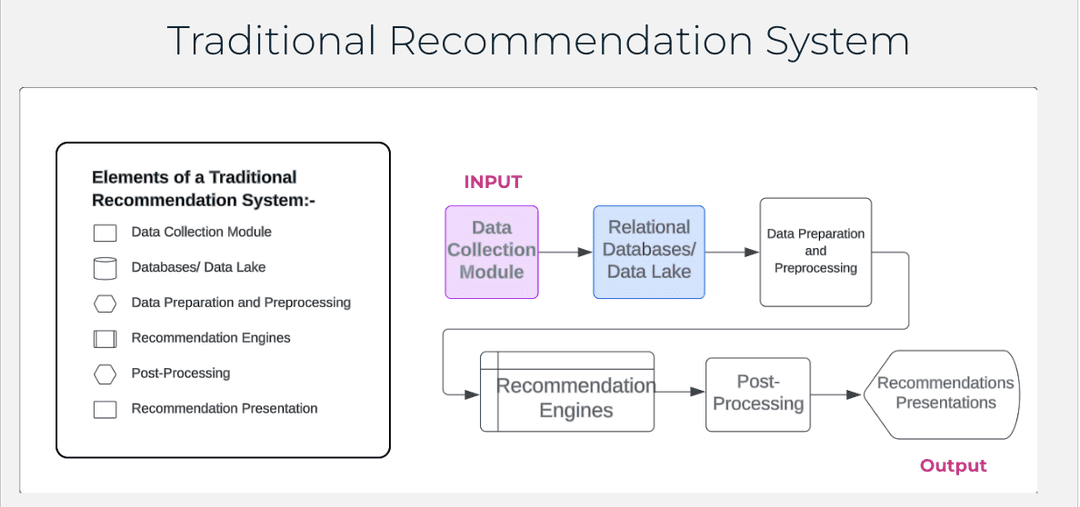
How do Web Scraping and Graph Databases Power Recommendation Engines?
Let’s understand through baking a cake analogy.
Context 1: Baking a Cake at Home
When you're baking a cake at home, you follow a certain process:
Decide which cake you want to bake.
Decide on the recipe.
Get the ingredients.
Prepare the ingredients.
Bake it in the oven.
Taste the cake.
This process mirrors a basic recommendation system, where you gather data (ingredients), process it (prepare the ingredients), apply a model or algorithm (bake it in the oven), and then evaluate the results (taste the cake).
Context 2: Running a Bakery
Now, imagine you're a pastry chef and own a bakery.
How can you improve the process of baking a cake for this context, taking into account the large scale of production and complexities associated with it?
Improving the Quality of Ingredients (Quality Data): Buy good quality raw materials and store them properly. In the context of a recommendation engine, this means gathering high-quality, relevant data from the web.
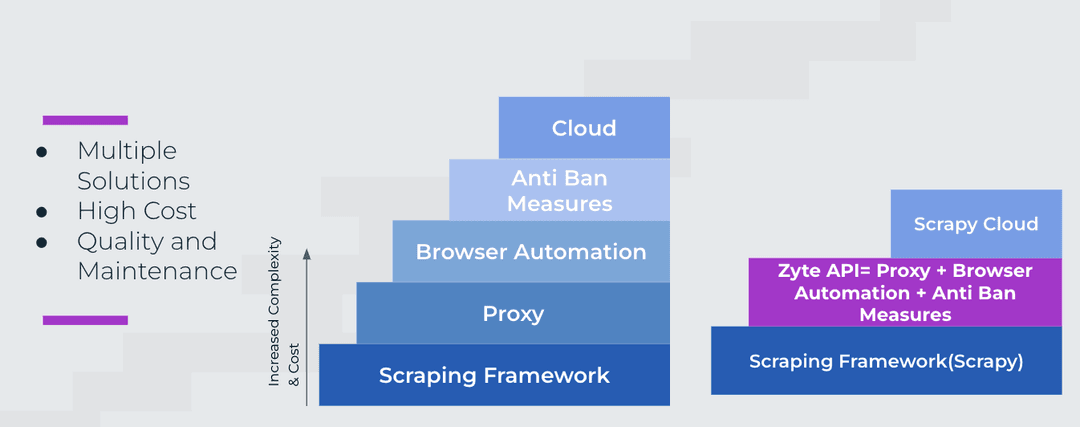
The challenge of sourcing large volumes of quality data from the web is the need to integrate multiple tools and technologies such as Scraping Frameworks, Proxy providers, Headless Browsers, Anti-Ban Measures and more. That level of complexity comes at a high cost, and issues with quality and maintenance. Luckily Tools like Zyte API address these challenges and make scraping the web a lot easier handling most of the heavy lifting of scraping at scale. It ensures you can easily gather high-quality reliably, which is crucial for the effectiveness of your recommendation engine.Choosing the Right Storage (Suitable Database): Just as ingredients need to be stored in suitable conditions to maintain their quality, data needs to be stored in a suitable database. Here, graph databases like Neo4j come into play. Graph databases offer a more natural representation of data, are flexible, and can adapt to the dynamic nature of the web. They are efficient in handling and representing complex relationships, which can help discover new relationships that never existed before. This makes them an excellent choice for storing data for recommendation engines.
Feedback Loop (Learning and Improving): Learn new techniques, and form new recipes by discovering new relationships between ingredients. For a recommendation engine, this involves using feedback from users to continuously improve the recommendations.
Building the System Keeping Context/Use-Case in Mind (Tailoring the Recommendations): When designing a process or a system, the ultimate goal should guide every step. For example, if you plan to bake a cake, you choose the type of cake, select the recipe, gather the ingredients, store them appropriately, prepare the mixture, bake it, and finally, taste-test the cake to garner feedback for future baking endeavours. This concept also applies to a recommendation engine in technology, which should be designed keeping the specific use case and the individual user's preferences in mind. Here, tailoring recommendations becomes vital. The engine should not merely suggest random options; instead, it should customize its suggestions based on user behaviour, tastes, and context. This tailored approach enhances the relevance of the recommendations, creating a more satisfying and engaging user experience, thus optimizing the effectiveness of the overall system.
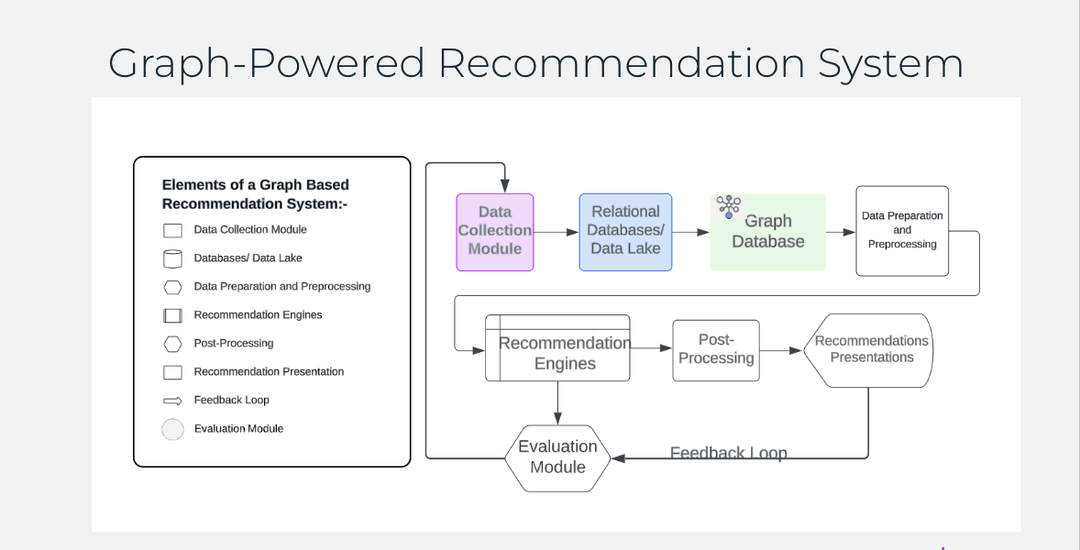
To conclude, By applying these principles, we can improve the traditional recommendation engine to provide more personalized and relevant recommendations. The choice of a suitable database, particularly a graph database like Neo4j, plays a crucial role in this improvement by providing a more natural and efficient representation of data and relationships. The use of tools like Zyte API ensures that the data going into the recommendation engine is of high quality and reliable, which is essential for the effectiveness of the recommendations.
Let’s understand this concept further with a real-world example.
Storing Reading Journeys in Graph Databases for Enhanced Self-Help Recommendations
In the realm of self-help literature, the reading journey of a user can be a powerful tool for personal growth and development. By tracking and analyzing these journeys, we can provide personalized recommendations that align with a user's goals and aspirations. Data Collection through Web Scraping and storing in Graph databases like Neo4j can play a pivotal role in this process. Here's how:
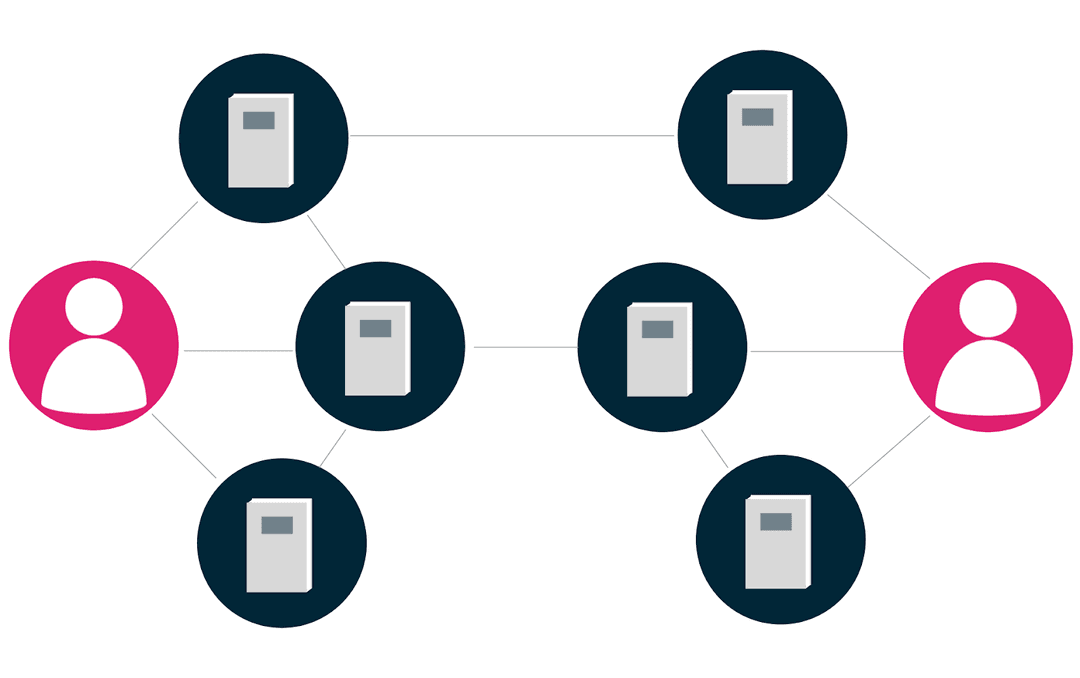
Collecting the Data: Web scraping can be used to gather data about various books, such as their genres, authors, publication dates, and user reviews from different online sources. For this specific case of creating a recommendation engine for self-help literature, these data sources could encompass online bookstores.
Large-scale web scraping, while useful, comes with distinct hurdles. Technically, it can be impeded by anti-scraping measures on websites, such as CAPTCHAs or IP blocking, and it demands significant computational resources due to the volume of data. Legally and ethically, it's vital to scrape respectfully and to abide by applicable laws, including intellectual property laws and data protection laws. Ignoring these can lead to legal troubles and reputational damage. As such, large-scale web scraping necessitates careful strategy, appropriate tools, and a thorough understanding of the technical, legal, and ethical landscape.
With services like Zyte API Enterprise, you can effectively break the painful cycle of build, break, fix, ban, and unblock, while maintaining global compliance as you scrape even the most complex websites. It’s the dynamic duo that will supercharge your data-scraping team.
Capturing the Reading Journey & Storing Book Data: In creating a comprehensive system for personalized recommendations, the first crucial step is to capture the reading journey. It involves documenting which self-help books a user has read, their specific ratings and reviews of these books, and the chronological order in which they were read. Each book a user interacts with becomes a distinct node in our graph, with attributes such as book details and the user's review score. The sequence of reading forms directed edges between these book nodes. This data representation not only creates a visual layout of a user's reading journey but also helps the system comprehend the user's interaction pattern with various books.
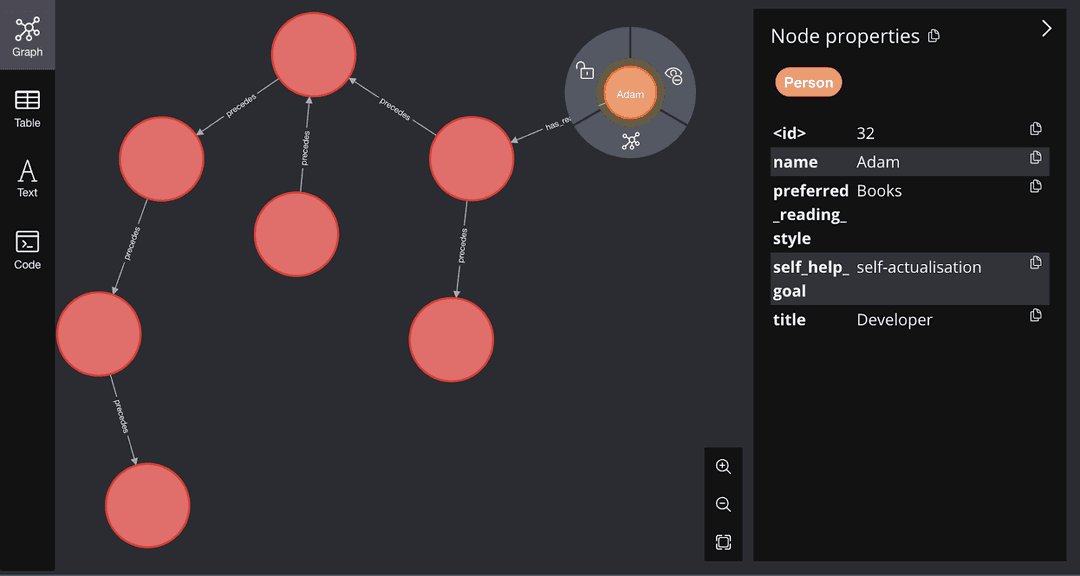
Storing User Profiles & Personal Preferences: Parallelly, another vital aspect to consider is the user's profiles. These profiles are also stored as nodes within the graph database. Each user node houses essential information about the user, such as their self-help goals, preferred reading style (like books, articles, podcasts), and their feedback on the content they've interacted with. Storing the topics of the books the user has read within the user node allows for a quick analysis of the user's interests. These detailed profiles become instrumental in understanding the user's needs and preferences. By harnessing this data, we can provide more personalized and thus more engaging and effective recommendations.
Creating Reading Paths: Based on the reading journeys and user profiles, we can create curated reading paths. These paths are sequences of books that have been beneficial to users with similar profiles. For example, if a user has a goal of improving their leadership skills, we could recommend a reading path that includes books on leadership that have been highly rated by users with similar goals.
Personalized Recommendations: When a new user comes to the platform, we can use their profile to match them with similar existing users in the graph database. We can then recommend the reading paths that have been beneficial to these similar users. This way, the new user gets a curated and personalized reading path that aligns with their self-help goals.
Updating the Graph: As users progress on their reading journey, they provide feedback, ratings, and reviews. This new data can be used to update the graph database, refine the reading paths and improve the accuracy of future recommendations.
Graph databases are particularly suited for this task due to their ability to efficiently handle complex relationships between entities (like users and books) and to uncover deep insights based on these relationships. They are flexible and can easily incorporate new types of data or relationships, making them ideal for the dynamic nature of personalized recommendations. Now you can use this database to train adaptive learning algorithms which will create a powerful recommendation system that provides users with curated reading paths for self-help. This not only enhances the user experience but also supports better in guiding users in their personal growth journey.
Wrapping Up and Looking Ahead
Ultimately, the aim is to create recommendation systems that do more than just suggest relevant items to users. They should understand and cater to the unique needs and preferences of each user. By leveraging web scraping for data collection and graph databases for data storage and analysis, we can make significant strides towards achieving this goal.
Web scraping, especially with tools like Zyte API, ensures high-quality and relevant data for our recommendation engines. Graph databases, like Neo4j, provide an efficient way to represent and manage complex relationships within our data, allowing us to visualize and understand the intricate network of interactions within a recommendation system.
Whether you're a data scientist, a developer, or a tech enthusiast, I hope this blog has provided you with valuable insights and sparked your curiosity to further explore the fascinating world of Thinking in Systems, Web Scraping, Graphs and recommendation engines. I hope the tools and techniques discussed in this blog will guide our way.
Reference Material :
1. Follow the Starter guidelines and extraction Code for this tiny demo here.







_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
