Python is a popular programming language among data-focused developers, it’s well suited to multiple aspects of accessing and structuring data from the web, and the world’s most popular scraping framework (Scrapy) is written in python. Python’s readability ensures that code is easily maintainable. There are many different libraries available for scraping, allowing users to choose one that suits their preferences and needs. Python is flexible and versatile, enabling work across various platforms, too.
This article explores the advantages of using Python for web scraping, the setup and basics, how different Python libraries and an API are used, and some prevalent challenges.
Designing your Project and Setting Up Your Environment
When designing a system to access, structure and store data in any language, the first thing to do is consider factors such as the volume of requests/pages, how fast you need to make them, how often, and how much much you want to build versus how much of your system you can offload.
Think about these factors before you start coding and you won’t end up in a situation where you get caught up by things like bans, or needing browsers, or needing to lower costs to come in under budget.
There is no one size fits all, but a bit of planning before you build anything will make your life a lot easier, and give you cost-effective shortcuts to getting your data faster, and cheaper at scale.
Setup
To begin web scraping with Python, you need to set up the appropriate environment. Python 3.7 or later is recommended due to its enhanced performance, security features, and compatibility with the latest libraries we will discuss. Some useful environments for your web scraping projects could take the form of an IDE. Two that are recommended are Pycharm by Jet Brains, and VS Studio code (open source). Both are great options and will support you when scraping with Python.
The libraries essential for Python web scraping are:
1. Scrapy: A powerful framework for large-scale web scraping.
2. BeautifulSoup: For parsing HTML and XML documents.
3. Selenium: Used for rendering dynamic content that requires JavaScript execution.
The best way to install these libraries is to use Pip (widely used to make installing modules much easier). To install Pip on Windows, go to https://bootstrap.pypa.io/get-pip.py, right click on the page, select “save as” and choose a directory. Then in a command window in that directory run “python get-pip.py”. Once complete, you can check you’ve done this correctly with “pip --version” in the command line.
Here is a quick overview on the installation of these libraries using pip in the cmd:
1. pip install selenium (You may need the latest ChromeDriver from (“https://googlechromelabs.github.io/chrome-for-testing/” )
2. pip install beautifulsoup4
3. pip install Scrapy
Understanding the Basics
HTML is the standard language for creating Web pages. HTML stands for Hyper Text Markup Language and is the standard markup language for creating web pages. It describes the structure of a web page and consists of a series of elements. These HTML elements tell the browser how to display the content and label pieces of content such as "this is a heading," "this is a paragraph," "this is a link," etc.
HTML is written with tags such as the paragraph “
”, tag with its corresponding “
” tag to end the text in the paragraph. These tags enclosepython
1<p> This is a paragraph</p>would create a paragraph of text that is displayed on the web page as “This is a paragraph.”
HTTP is a method by which you receive web content. HTTP stands for Hyper Text Transfer Protocol. The typical process is as follows: a client, typically a web browser, sends an HTTP request to the web server. The web server receives this request and runs an application to process it. After processing, the server returns an HTTP response containing the requested information or resources back to the browser. Finally, the client, which is the browser, receives the response and displays the content to the user.
To learn how to scrape the web it is important to know how to inspect web pages to identify the necessary data. Web browsers come with built-in developer tools that make it easy to inspect web pages. A method to access this function is to right click on the web page and select “Inspect element”. This will show the HTML elements of the page, hovering over these sections will highlight these on the page once the required data is located, a right click on the HTML will give the option to copy a selector, which is what is used in scraping scripts to work with page elements.
There is also a chrome extension to make selection these elements even easier recommended by Selenium documentation which is SelectorsHub. After installing this extension, select the necessary element within the elements panel and it will provide various attributes, XPath, and CSS selectors generated for the selected element making the process more efficient.
Using BeautifulSoup for Web Scraping
Beautiful Soup is a Python library for pulling data out of HTML and XML files.
To parse HTML with it:
1. Install Beautiful Soup (pip install beautifulsoup4 in terminal a. Install a Parser (pip install html5lib)
2. Run your code through BeautifulSoup with commands such as “print(soup.prettify())” to make the HTML better formatted and more readable
Example:
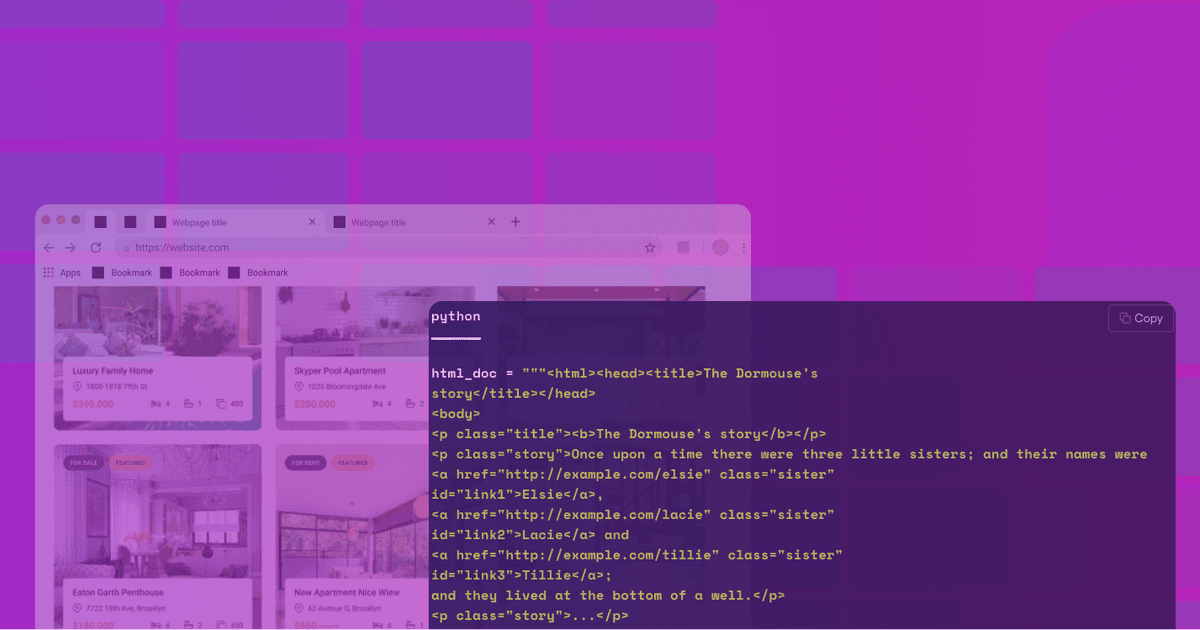
python
1html_doc = """<html><head><title>The Dormouse's
2story</title></head>
3<body>
4<p class="title"><b>The Dormouse's story</b></p>
5<p class="story">Once upon a time there were three little sisters; and their names were
6<a href="http://example.com/elsie" class="sister"
7id="link1">Elsie</a>,
8<a href="http://example.com/lacie" class="sister"
9id="link2">Lacie</a> and
10<a href="http://example.com/tillie" class="sister"
11id="link3">Tillie</a>;
12and they lived at the bottom of a well.</p>
13<p class="story">...</p>
14"""Is an excerpt from “Alice in Wonderland”. To run it through BeautifulSoup, you can format it as such:
python
1from bs4 import BeautifulSoup
2soup = BeautifulSoup(html_doc, 'html.parser')Now you can use commands such as:
python
1soup.title
2# <title>The Dormouse's story</title>To Pull the title of the Document. Another common task is extracting all the URLs found within a page’s tags:
python
1for link in soup.find_all('a'):
2print(link.get('href'))
3# http://example.com/elsie
4# http://example.com/lacie
5# http://example.com/tillieWeb Scraping with Scrapy
Scrapy is an open-source web crawling framework. It is designed for large-scale web scraping and provides all the tools needed to extract data from websites, process it, and store it in your desired format with minimal effort. It can be used for a wide range of useful applications, like information processing or historical archival.
Its architecture is flexible and efficient. Its parts include: Its Engine, Scheduler, Downloader, Spiders, Item pipeline and more.
To create a Scrapy project:
1. Install the library (pip install Scrapy in terminal)
2. Run: scrapy startproject, followed by the name of your project. This will create a directory for your Scrapy Project
Example:
python
1import scrapy
2class QuotesSpider(scrapy.Spider):
3name = "quotes"
4start_urls = [
5"https://quotes.toscrape.com/tag/humor/",
6]
7def parse(self, response):
8for quote in response.css("div.quote"):
9yield {
10"author": quote.xpath("span/small/text()").get(),
11"text": quote.css("span.text::text").get(),
12}
13next_page = response.css('li.next a::attr("href")').get()
14if next_page is not None:
15yield response.follow(next_page, self.parse)This scrapes quotes from the URL: https://quotes.toscrape.com. Saving this as a Python file then launching from terminal with:
python
1scrapy runspider quotes_spider.py -o quotes.jsonlOnce complete you're left with a file in the directory:
python
1{"author": "Jane Austen", "text": "\u201cThe person, be it gentleman or lady, who has not pleasure in a good novel, must be intolerably stupid.\u201d"}
2{"author": "Steve Martin", "text": "\u201cA day without sunshine is like, you know, night.\u201d"}
3{"author": "Garrison Keillor", "text": "\u201cAnyone who thinks sitting in church can make you a Christian must also think that sitting in a garage can make you a car.\u201d"}
4…Also, you can select CSS elements:
python
1response.css("title::text").getall()
2['Quotes to Scrape']This returns the title.
Example:
python
1import scrapy
2class BookSpider(scrapy.Spider):
3 name = 'book'
4 start_urls = [
5 'http://books.toscrape.com/catalogue/a-light-in-the-attic_1000/index.html',
6 ]
7
8 def parse(self, response):
9 yield {
10 'title': response.css('div.product_main h1::text').get(),
11 'price': response.css('p.price_color::text').get(),
12 'availability': response.css('p.instock.availability::text').re_first('\d+'),
13 }Save this spider as bookspider.py and then you can run the spider
python
1scrapy runspider bookspider.py -o book_data.jsonbook_data.json will contain this data
python
1[
2 {"title": "A Light in the Attic", "price": "\u00a351.77", "availability": "22"}
3]This basic spider will visit the specified URL, extract price from the page, and download that data.
Web Scraping with Python and Selenium (a headless browser)
Selenium is a powerful tool for automating web browsers. It is highly effective for web scraping, especially when dealing with dynamic web content that is generated by JavaScript. Selenium can interact with web pages just like a human user.
This includes clicking buttons, filling out forms, and waiting for JavaScript to execute, making it ideal for scraping content from modern, dynamic websites.
To use Selenium with Python as covered previously use “pip install selenium” and use the correct chromedriver version. This is a basic example of setting up a headless script:
python
1from selenium import webdriver
2from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By
3from selenium.webdriver.common.keys import Keys
4from selenium.webdriver.chrome.options import Options
5# Set up the Chrome driver
6chrome_options = Options()
7chrome_options.add_argument("--headless") # Run in headless mode
8service = Service('/path/to/chromedriver')
9driver = webdriver.Chrome(service=service,
10options=chrome_options)
11# Open the webpage
12driver.get('https://example.com')
13# Wait for JavaScript to load and find an element
14element = driver.find_element(By.XPATH, '//h1')
15print(element.text)
16# Close the browser
17driver.quit()In this example, Selenium is used to open a webpage, wait for the JavaScript to execute, and then find and print the text of an
element. The browser runs in “headless” (line 9) mode, meaning it operates in the background without opening a visible window.
Example 2:
python
1from selenium import webdriver
2from selenium.webdriver.chrome.service import Service from selenium.webdriver.common.by import By
3from selenium.webdriver.chrome.options import Options from selenium.webdriver.support.ui import WebDriverWait
4from selenium.webdriver.support import expected_conditions as EC
5# Set up the Chrome driver
6chrome_options = Options()
7chrome_options.add_argument("--headless") # Run in headless mode
8service = Service('/path/to/chromedriver')
9driver = webdriver.Chrome(service=service,
10options=chrome_options)
11# Open the webpage
12driver.get('https://www.example-ecommerce.com')
13# Wait for the product elements to be loaded
14WebDriverWait(driver, 10).until(
15EC.presence_of_all_elements_located((By.CLASS_NAME, 'product-item'))
16)
17# Scrape product details
18products = driver.find_elements(By.CLASS_NAME, 'product-item') for product in products:
19name = product.find_element(By.CLASS_NAME,
20'product-name').text
21price = product.find_element(By.CLASS_NAME,
22'product-price').text
23print(f'Product Name: {name}')
24print(f'Price: {price}')
25print('---')
26# Close the browser
27driver.quit()This example demonstrates how to use Selenium to scrape product details from a JavaScript-heavy e-commerce website. By setting up the Chrome driver, waiting for the necessary elements to load, and extracting the desired data, you can effectively scrape dynamic content.
Why Selenium Should Be a Tool of Last Resort
Selenium should be considered a tool of last resort for web scraping due to its high resource consumption, slower execution, and increased infrastructure costs. Running a full browser session with Selenium, even in headless mode, is resource-intensive, consuming significantly more CPU and memory compared to other web scraping tools that do not need to render JavaScript. This results in slower execution times, as each interaction with the page—such as clicking, typing, and waiting for JavaScript to load—adds to the overall time required to scrape data. Additionally, large-scale scraping projects with Selenium demand substantial computational resources and infrastructure, leading to higher costs for servers and maintenance. The complexity of setting up and managing Selenium-based scraping projects is also higher than using lightweight libraries like BeautifulSoup or Scrapy. Debugging and maintaining Selenium scripts can be more challenging due to the dynamic nature of the content being scraped. Therefore, while Selenium is effective for scraping JavaScript-heavy websites, its use should be carefully considered and reserved for situations where simpler and more efficient tools are inadequate.
Web Scraping with Python and Zyte API
Web Scraping APIs are a tool developers can wire into their scraping code to offload and handle many aspects of scraping projects, from taking care of proxies and bans, to using their hosted browsers and more.
There are many advantages to using these APIs, from lowering development time when building spiders to benefiting from their economies of scale, and lowering your mental load. They host and maintain all the infrastructure needed and are on top of the latest developments so you can always be up to date with the fast moving world of web scraping and anti-bot.
Zyte API, in particular, has several other benefits too, all aimed at making data teams more agile, productive, and free to scale, and helping you build systems that are more robust and cost-effective too.
How Using Zyte API Saves Time
Using Zyte API significantly saves time for developers and businesses because it comes with everything a scraping system needs already available.
Zyte API includes headless browsers, smart IP rotation, and automatic data extraction capabilities. You do not need to invest time in setting up all that infrastructure project by project, managing proxy configurations, or dealing with the complexities of browser automation. That's all taken care of for you. Simply send requests to the API with parameters to tell it what config you want. Browser, no browser, geo-location, session details etc… and it will handle the request, no fuss, just the data you need.
Zyte API’s built-in features, such as anti-ban mechanisms and seamless handling of JavaScript-rendered content, further streamline the scraping process. By offering a ready-to-use solution, Zyte API allows developers to focus directly on extracting and utilizing data, rather than spending valuable time on setup and troubleshooting. This approach not only accelerates project timelines but also reduces operational overhead, making it a highly efficient choice for web scraping tasks.
Conclusion
In this ultimate guide to web scraping with Python, we've covered the fundamental aspects of setting up your environment, understanding the basics of HTML and HTTP, and using key libraries such as BeautifulSoup, Scrapy, and Selenium. Each of these tools offers unique capabilities that cater to different scraping needs, from simple HTML parsing to handling dynamic web content. Additionally, we introduced Zyte API, which provides a comprehensive solution with features like smart proxy management, headless browsing, and automatic data extraction, ensuring a robust and scalable web scraping setup.
Structuring and cleaning your data before storage in formats like CSV, JSON, or databases ensures that it is ready for analysis and use. Efficient data management practices enhance the quality and reliability of your data extraction processes.
To get started with web scraping in Python, focus on learning the basics and gradually move on to more complex tasks. Using tools like Zyte API can significantly simplify the process and provide added reliability with features such as anti-ban mechanisms and geolocation support.
Finally, continuous learning and staying updated with new tools and techniques are vital. The field of web scraping is constantly evolving, and keeping abreast of the latest developments will ensure your scraping activities remain efficient, compliant, and effective. For more detailed information and resources, refer to Zyte's comprehensive guides and case studies.
Try Zyte API
Zyte proxies and smart browser tech rolled into a single API.
FAQs
What is the best Python library for web scraping?
The best library depends on your needs: use BeautifulSoup for simple HTML parsing, Scrapy for large-scale scraping, and Selenium for dynamic JavaScript content.
How do I inspect web pages to identify the data I need?
Use browser developer tools by right-clicking a page element and selecting "Inspect" to view its HTML structure and extract selectors.
Why is Selenium considered a last resort for web scraping?
Selenium is resource-intensive and slower compared to libraries like BeautifulSoup or Scrapy, making it suitable only for scraping JavaScript-heavy websites.
What are the advantages of using the Zyte API for web scraping?
The Zyte API simplifies scraping by managing proxies, bans, and JavaScript rendering while reducing setup time and infrastructure costs.
What is the recommended Python version for web scraping?
Use Python 3.7 or later for optimal performance, security, and compatibility with modern scraping libraries.





_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
