Businesses that thrive on search engine data use Zyte
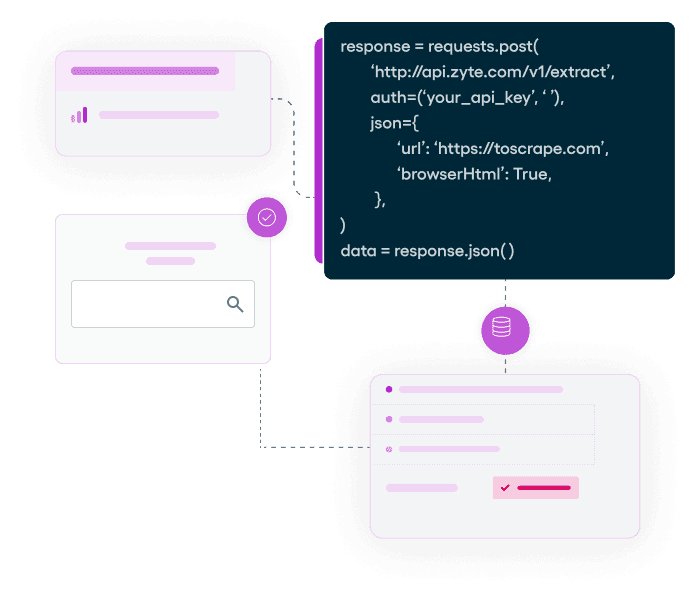
Web data your way - Build or Buy?
Find the fastest route to quality search engine scraper data for you
Developer
from
$
0.8 /
10.000 requests
The most complete and advanced AI-powered search engine scraper with anti-ban and headless browser solution.
Data Buyer
From
$
450
/month
Don’t waste time scraping the same e-commerce websites we already do on a regular basis.
The fastest way to get rock solid, reliable e-commerce product data.
Types of search results
Traditional search engine scraping
Extremely broad and deep search data from search engines
Search engine scraping can be difficult at scale.
Challenges include:
- Type of data
- Location
- Changing layouts
- Broken templates, selectors, and anti-ban solutions.
Zyte has the perfect products for scraping search results.
Emerging search content
Search isn’t just 10 blue links anymore
Within traditional search engine scraping, there are multiple sub-sets of search such as:
Image search
Video search
Product search
Social search
Vertical search engines
Travel search
Semantic search
News search
Music search
Academic search
Medical search
Torrent search
Recipe search
Job search
Government search
Blog search
Podcast search
Code search
Legal search
Real estate search
Patents search
Book search
Local search
Find the best way to collect web data from search engines
Don't reinvent the wheel
We probably already extract web data from search engines with our search engine result scraper from your target website and can offer the data you need in a standardized schema that will make your life easier and save you time and money.
Use our web scraping API
Zyte API is the ultimate web search engine web scraping API, designed to automatically avoid bans in the most cost-effective way possible saving you time and money at every stage of your project.
How will you use search engine data?
Rank monitoring
Scraping search engines to see which websites rank in which positions in search engines for any given keyphrase by automating the process of performing a search and parsing the results to extract positions.
In-search results feature monitoring
Search engines show more than links to websites, often trying to answer questions and provide insights and suggestions. Using search engine scraping to access search engine data can be invaluable to businesses.
Search advertisement monitoring
Want to know who is advertising in search engines on specific keywords? Scraping search engines sponsored results section to track and understand the search advertising landscape.
Aggregating results pages across multiple search engines
By combining the search results from multiple sites you can build a more complete picture of a niche or industry.
Copyright detection and enforcement
As search engines index large amounts of content from the entire web, you can use search engine scrapers to help identify websites infringing on copyright using smart search parameters and filters.
Dynamic price monitoring
Given a product-related search phrase search engines often surface product pricing information from a variety of sellers. You can use that web scraping data to monitor pricing.
Relative price optimisation
Use web scraping to understand the relative prices of related products available through search engines, and/or monitor pricing for specific items in search engines.
Analyzing algorithms and suggestions
One way to test and understand other search engines algorithms is to observe the results they provide. From related product recommendation engines to related search suggestions, web scraping is one way to better understand what is driving popular search engines algorithm.
Monitoring for new business locations
Major search engines provide an element of location-based search. You can use search engine scrapers as a way to find new businesses along with their related data.
Trend analysis on jobs and marketplaces
In fast-moving industries and marketplaces, search engines can be useful to help you build a picture of your business landscape and monitoring competitors - eg. Which cities are seeing the most growth in jobs available and increase in accommodation pricing?
Enterprise Ready
As the global leader for 12+ years, Zyte has developed the expertise, processes and technology that guarantees success for our clients.
Our dedicated customer success managers partner with your team to ensure best-in-class advice and web scraping results - guaranteeing quality and performance with 24/7 monitoring and support.
Keep up-to-date with trends in web data extraction
Webinar
Case Study
White Paper / eBook
Frequently asked questions
Is Zyte the same as Scrapinghub?
Different name. Same company. And with the same passion to deliver the world’s best data extraction service to our customers. We’ve changed our name to show that we’re about more than just web scraping tool. In a changing world Zyte is right at the cutting edge of delivering powerful, easy to use solutions that help our customers stay ahead in today’s fast-moving, data-driven world.
How will I receive my data, and in what format?
We offer many delivery types including FTP, SFTP, AWS S3, Google Cloud storage, email, Dropbox and Google Drive. Formats for delivery can be CSV, JSON, JSONLines or XML. We’ll work with you to determine what’s best for your project. And we’re always pleased to discuss other custom delivery or format requirements should you need them.
What data can you provide me?
We have the technical capability to extract any website data. However, there are legal considerations that must be adhered to with every project, including scraping behind a login as well as compliance with Terms and Conditions, privacy, and copyright laws. When you submit your project request our solution architects and legal team will pinpoint any potential concerns in extracting data from websites and ensure that we follow web scraping best practices.
How will you manage my data project?
After you’ve submitted your project request, a member of our solution architecture team will quickly get in touch to set up a project discovery call. They’ll explore your requirements of data extraction from websites in detail and gather the information they need, including:
What site[s] do you want to crawl?
What data do you need to extract?
What’s the scale of your scraping requirement?
Does your data need transformation?
What integrations are needed?
Once our architects know your requirements to extract data from webpages, they’ll propose the optimal solution - usually within a couple days - for your approval.
How do you ensure quality of the data?
We specialize in data extraction solutions for projects with mission critical business requirements. And that means our top priority is always delivering high quality accurate data to our clients. To achieve this we’ve implemented a four-layer Data Quality Assurance process that continuously monitors the health of our crawls and the quality of the extracted data. This reviews all your data to identify inconsistencies, inaccuracies or other abnormalities including manual, semi-automated and automated testing.
What support do you offer?
We offer all our customers no-cost support on coverage issues, missed deliveries and minor site changes. If there’s a larger website data extraction change that requires a complete spider overhaul this may incur an additional cost.
Can I try Zyte before buying?
Yes, if we have sample data available for the source you want to be scraped. If it’s a new source we haven’t crawled before we will share sample data with you following development kick-off. This occurs post purchasing. For product or news & article data, you can free trial our Automatic Extraction product via an easy-to-use user interface.
Talk to us about your requirements
How can Zyte help me extract website content?
Zyte’s Data Extraction services is an end-to-end solution that can help you with web content extraction. It’s the most hassle-free way to get clean structured data; quickly and accurately. But if you’re looking for a DIY option, Zyte offers web data extraction tools to make your job easier.
What is meant by data extraction?
Data extraction is described as the automated process of obtaining information from a source like a web page, document, file or image. This extracted information is typically stored and structured to allow further processing and analysis.
Extracting data from Internet websites - or a single web page - is often referred to as web scraping. This can be performed manually by a person cutting and pasting content from individual web pages. This is likely to be time-consuming and error-prone for all but the smallest projects.
Hence, data extracting is typically performed by some kind of data extractor - a software application that automatically fetches and extracts data from a web page (or a set of pages) and delivers this information in a neatly formatted structure. This is most likely a spreadsheet or some kind of machine-readable data exchange format such as JSON or XML. This extracted data can then be used for other purposes, either displayed to humans via some kind of user interface or processed by another program.
Why is data extraction important?
There’s a vast amount of information out there on the Internet. Extracting and aggregating data from public-domain websites and other digital sources - also known as web data scraping - can give you a significant business edge over your competitors.
Data extracting generates insights that can help companies analyze the performance of a particular product in the marketplace, track customer sentiments expressed in online reviews, monitor the health of your brand, generate leads, or compare price information across different marketplaces.
It also gives researchers a powerful tool to study the performance of financial markets and individual companies, guide investment decisions and shape new products.
There are many non-financial uses for data extraction, such as scraping news websites to monitor the quality and accuracy of stories or to monitor trends in reporting. It’s also used to obtain information from public institutions, for example, to track contract awards and hence investigate possible corruption.
Data extraction can significantly streamline the process of getting accurate information from other websites that your own organization needs to survive and thrive.
What is a data extraction example?
There’s a vast range of applications and use cases for website data scraping. One popular example where data extraction is widely used comes from the world of retail and e-commerce. It’s an invaluable tool for competitor price monitoring, allowing companies – and market researchers – to monitor the pricing of rivals’ products and services. Manually tracking competitors’ prices that may change on a daily basis isn’t practical - especially if you’re monitoring the pricing of hundreds or thousands of different products. A data scraping tool automates this process, scraping pricing data from e-marketplaces and competitors’ websites quickly and reliably.




_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
