
How to scrape the web without getting blocked
Web scraping is when you extract data from the web and put it in a structured format. Getting structured data from publicly available websites and pages should not be an issue as everybody with an internet connection can access these websites. You should be able to structure it as well. In reality, though, it’s not that easy.
One of the main use cases of web scraping is in the e-commerce world: price monitoring and price intelligence. However, you can also use web scraping for lead generation, market research, business automation, among others.
In this article, you will learn what are the subtle ways a website can recognize you as a bot and not a human. We also share our knowledge on how to overcome these challenges and how to crawl a website without getting blocked and access publicly open web data.
Best Practices to Scrape the Web
At Zyte (formerly Scrapinghub), we care about ensuring that our services respect the rights of websites and companies whose data we scrape.
There’s a couple of things to keep in mind when you’re dealing with a web scraping project, in order to respect the website.
Check robots.txt
Always inspect the robots.txt file and make sure you respect the rules of the site. Make sure you only crawl pages that are allowed to be crawled.
Don't be a burden
If you want to scrape the web, you should be really careful with the manner of your requests because you don’t want to harm the website. If you harm the website that’s not good for anybody.
- Limit your requests coming from the same IP address
- Respect the delay between requests that are outlined in robots.txt
- Schedule your crawls to run off-peak hours
Still, even when you are careful with your scraper, you might get banned. This is when you need to improve how you do web scraping and apply some techniques to get the data. But remember, be nice how you scrape! Read more about best practices.
What are anti-bots?
Anti-bot systems are created to block website access from bots that scrape the web. These systems have a set of approaches to differentiate bots from humans.
Anti-bot mechanisms can mitigate DDOS attacks, credential stuffing, and credit card fraud. In the case of ethical web scraping though, you’re not doing any of these. You just want to get access to publicly available data, in the nicest way possible. Often the website doesn’t have an API so you have no other option but scraping it.
Anti-bot mechanisms
The core of every anti-bot system is that they try to recognize if an activity is done by a bot and not a human. In this section, we’re going through all the ways a bot can be caught, while trying to scrape the web for access to a specific website.
Header validation
When your browser sends a request to the server, it also sends a header. In the header, you have several values and they are different for each browser. Chrome, Firefox, Safari all have their own header patterns. For example, this is what a chrome request header looks like:
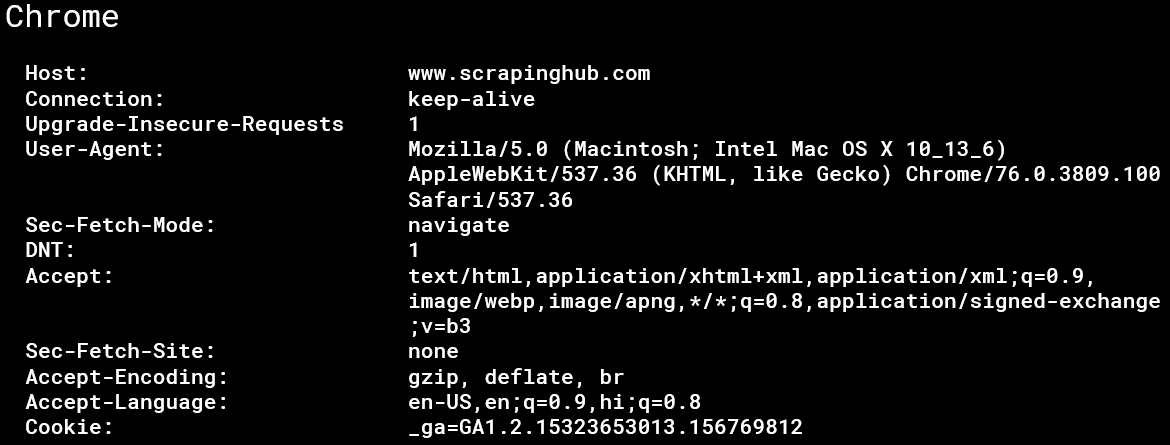
A bot can be easily recognized if the header pattern is not equivalent to a regular browser. Or if you’re using a pattern while you scrape the web, that is inconsistent with known browsers’ patterns you might get throttled or even blocked.
User-agent
When you started to scrape the web you probably had user-agents like these:
- curl/7.54.0
- python-requests/2.18.4
Then, as you scrape the web, you realized it’s not enough to access the page so you need to set a custom user-agent that looks similar to a real browser. Like this:
Mozilla/5.0 (Windows NT 10.0; Win64; x64; rv:73.0) Gecko/20100101 Firefox/73.0
In the past, changing user-agent (user-agent spoofing) might have been enough to access a website but nowadays you need to do more than this.
TCP/IP fingerprinting
A more sophisticated way to detect bots is by using TCP/IP fingerprinting. TCP is the backbone of the internet. When you or your scraper uses the internet you are using TCP. TCP leaves a lot of parameters (like TTL or initial window state) that need to be set by the used device/operating system. If these parameter values are not consistent you can get caught.

For example, if you’re sending a request posing as a Chrome browser on Windows but your TTL (time to live) is 64 (maybe because you use a Linux-based proxy), your TTL value is not what it’s supposed to be (128) so your request can be filtered out as you scrape the web.
IP blocking
A lot of crawling happens from datacenter IP addresses. If the website owner recognizes that there are a lot of non-human requests coming from this set of IPs trying to scrape the web, they can just block all the requests coming from that specific datacenter so the scrapers will not be able to access the site.
To overcome this, you need to use other datacenter proxies or residential proxies. Or just use a service that handles proxy management.
Geo-blocking
Some websites intentionally block access if your request comes from a specific (or suspicious) region while one tries to scrape the web.
Another case where geographical location can be a challenge for you is when the website gives you different content based on where you are. This can be easily solved by utilizing proxies in the proper regions.
Detecting bots on the front-end
Moving away from the back-end side of things and how your scraper can be recognized as a bot on the back-end, there are some ways on the front-end as well that can get you in trouble when you scrape the web.
Javascript
Every browser needs to have javascript to render modern websites properly. Accordingly, if you scrape a website that shows content using JS you need to execute JS in your scraper as well. You can either use a javascript rendering service or a headless browser.
Regarding bot detection, if your scraper doesn’t have any JS rendering capabilities you can be easily detected as a bot. The website might make your scraper perform simple arithmetic operations just to test if it has JS. Javascript can be also used for AJAX requests/lazy loading or redirection.
Remember to be always be cautious when you scrape the web. If your scraper just sends a regular request without handling JS you will either not see the content at all or you can get recognized as a bot.
Browser fingerprinting
Browser fingerprinting is a combination of browser properties/attributes derived from Javascript API and used in concert with each other to detect inconsistencies. It contains information about OS, devices, accelerometer, WebGL, canvas, etc…

If there are some inconsistencies in this set of information, as you scrape the web, anti-bot systems can be triggered and the website starts showing you captchas or makes it difficult to scrape the site in some ways.
CAPTCHAs
Back in the day, captchas used HIP (Human Interactive Proof) with the premise that humans are better at solving visual puzzles than machines. Machine learning algorithms weren’t developed enough to solve captchas like this:
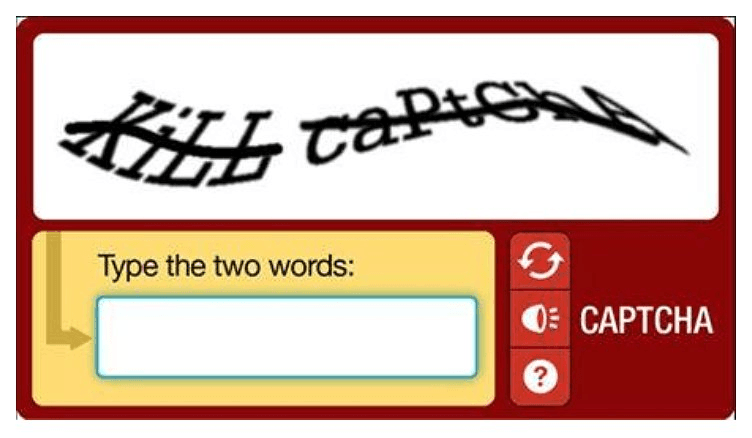
However, as machine learning technologies evolved, nowadays a machine can solve this type of captcha easily. Then, more sophisticated image-based tests were introduced, which gave a bigger challenge for machines.
Behavioral patterns
The most recent versions of captchas are much more transparent and user-friendly because they are based on behavioral patterns.
The idea behind these captchas is that it’s transparent to the user. They track mouse movements, clicks, and keystrokes. Human behavior to scrape the web is much more complex than bot behavior.
The key to handling modern captchas is to be smart about the manner of your scraping. If you can figure out what triggers the captcha for that specific site you’re dealing with, solve that problem first, instead of trying to handle the captcha itself.
Use more or different proxies (if you’ve been using datacenter IPs, try to switch to residential ones). Or make requests less frequently based on how the website reacts.
Request patterns
A bot is designed to be efficient and find the quickest way to extract data. Looking behind the curtain and using a path that is not seen nor used by a regular user.
Anti-bot systems can pick up on this behavior whenever anyone tries to scrape the web. Another important aspect is the amount and frequency of requests you make. The more frequent your requests (from the same IP) are the more chance your scraper will be recognized.
Wrapping up
It’s not an easy task to scale up your web scraping project and scrape the web effectively.
I hope this overview gave you some insights on how to maintain successful requests and minimize blocking. As mentioned above, one of the building blocks of a healthy web scraping project is proxy management.
If you need a tool to make web scraping easier, try Zyte Proxy Manager for free. Zyte Smart Proxy Manager's rotating proxy network is built with a proprietary ban detection and request throttling algorithm.
Zyte Proxy Manager will ensure your web scraped data is delivered successfully!







_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
