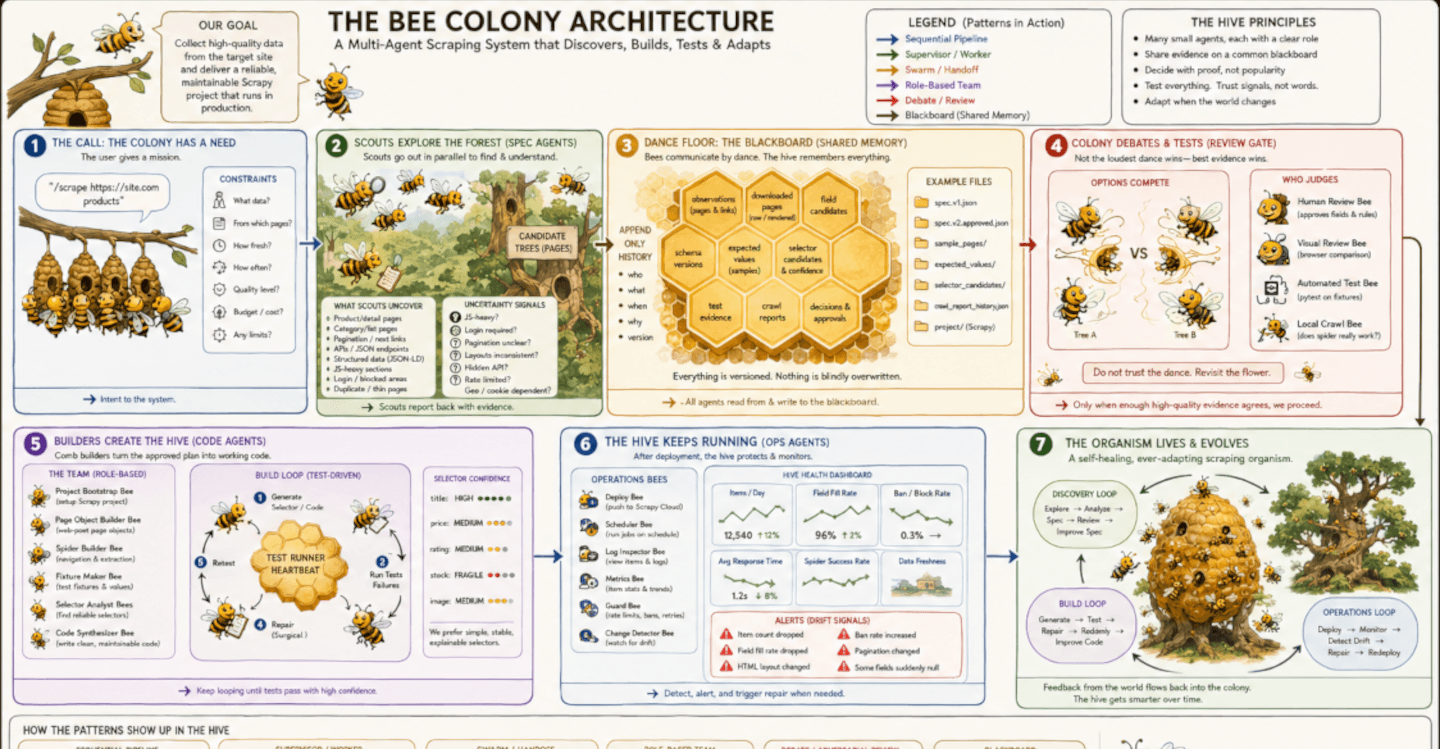
Multi-agent orchestration is having its moment. The diagrams are everywhere now. Boxes for planners, boxes for hands, boxes for daemons, arrows to a shared brain, a human floating at the top. They keep getting prettier.
The part where the web pushes back is still the part nobody draws.
That is the part I want to write about. Because if multi-agent orchestration is going to mean anything in production, it has to survive contact with messy real-world data. The cleanest test of any agent system is what happens when it tries to read the live web for the second week in a row when sites change layout, pages return empty and rate limits trigger.
Web scraping is what happens when an agent has to keep working anyway.
What keeps coming up in the conversations I have been having with engineers running scraping at scale is that the work is no longer a coding problem, it is an evidence problem. Real websites are not clean data vending machines. They are weather systems, mazes, locked gates, changing paths, false flowers, sticky mud, and occasionally angry gardeners. They change layout without warning, hide prices behind JavaScript, serve different content by region, paginate in ways nobody documented, return empty pages that look successful, and quietly remove fields the downstream pipeline depends on.
Multi-agent orchestration is the right architecture for this kind of environment. Not because AI is having a moment. Because honeybees, who have been doing distributed coordination for 100 million years, settled on something with roughly this shape and it works.
That is what this post is about. How a real scraping system thinks. How Claude Skills become the unit of specialization that lets you build one. And how a colony of small, focused agents working over a shared blackboard, sitting on top of Zyte API and Scrapy, gives you something closer to a living system than a one-off spider.
I will walk through it in seven scenes.
A short note on the bee metaphor and Claude Skills
Honeybees searching for a new home are probably the cleanest example of multi-agent orchestration that nature ever invented. Thousands of bees, no project manager with a clipboard, a swarm that can search, compare, converge, and move the whole colony to a new nest. They do this with specialized roles, distributed exploration, shared memory expressed as dances on a comb, evidence-weighted decisions, and feedback loops that keep adjusting until the swarm agrees. The architecture is older than us, and the same shape works for scraping.
A Claude Skill is how you encode one of those specialized roles. A skill is a folder with a SKILL.md file that tells Claude how to do one job well, plus any scripts, references, or templates that job needs. Claude reads the right skill when the right job comes up. One skill becomes one bee with a clear role. Many skills, coordinated by an orchestrator and writing to a shared blackboard, become a colony.
The rest of this post walks the seven scenes of a colony built to scrape.
Scene 1: The swarm has a need

Scene 1: the swarm has a need
Every scraping project starts with someone saying "we need data from this site." That is the bee colony saying "we need a new home." The instructions sound simple but it is not.
A real scraping request is a data contract, and the contract has at least six dimensions: what data, from which pages, how fresh, how often, what quality level, and what budget. Skip this step and the colony either builds the wrong hive or wastes a season scouting trees that were never going to work. The web outside is hostile and shifting, and starting the work without naming the contract is how you end up with a scraper that "works" but never tells you when the data has quietly drifted from what the business actually needs.
In the Claude Skills version, this is where an intake skill sits. Its job is not to scrape anything. Its job is to turn a fuzzy request into a structured spec the rest of the colony can act on: fields, page types, refresh frequency, acceptable cost, acceptable latency, fallback behavior. The output gets written to the blackboard as spec.v1.json, ready for the next set of agents to read.
The lesson under the metaphor lands right at the start. Clear requests make strong colonies, and most projects that go badly went badly here, not later.
Scene 2: The scouts reduce uncertainty

Scene 2: the scouts reduce uncertainty
It is tempting to say the next step is to look at the site. It is more accurate to say the next step is to reduce uncertainty.
When scouts come back from the forest, they are not just reporting "I found a tree." They are answering questions the colony cannot yet answer. Is this site JavaScript-heavy? Does it require login? Is the pagination consistent or does it break after page ten? Is the data in raw HTML, rendered HTML, JSON-LD, an embedded script, or a hidden API? Are there geographic variations? Are there duplicate listings under different URLs? Are there link types that look like product pages but are not? Each of these is a fork in how the spider eventually needs to behave, and getting it wrong early means getting the whole architecture wrong.
This is where scout agents earn their keep, and where Claude Skills start to multiply naturally. A detail page finder skill locates representative item pages. A page downloader skill captures raw HTML, rendered HTML, screenshots, and metadata into a structured sample set. A site explorer skill maps homepage, category pages, pagination structure, and detail link patterns. A link classifier skill separates item links from category links, pagination links, and noise. Page analyzer workers inspect multiple pages in parallel and write back what they find.
These are not generic bees with a checklist. They are specialists with different kinds of judgment, and they can run concurrently, with the orchestrator collecting their findings into a single growing picture.
The output of this phase is not just "some pages”, its confidence. The system should know what it is scraping, where the values come from, how reliable they look, and what remains uncertain. If the colony moves into building the hive before this stage is solid, every later decision rests on guesswork.
Scene 3: The dance floor remembers

Scene 3: the dance floor remembers
The most important architectural decision in a serious agent system is shared memory. Get this wrong and your colony forgets, contradicts itself, and rebuilds from scratch every time something breaks.
Real bees do not whisper findings to every other bee in the swarm. They return to a shared space and dance. The dance floor is the blackboard. In a scraping agent system, the blackboard is a structured project directory that every agent reads from and writes to.
A reasonable layout looks like this:
.scrape/site/
spec.v1.json
spec.v2.approved.json
sample_pages/
raw/
rendered/
screenshots/
metadata/
expected_values/
selector_candidates/
test_evidence/
crawl_reports/
review_feedback/
repair_history/
The production catch, the one that separates a useful system from a chaotic one, is this: shared memory is dangerous if everyone can overwrite it freely. The dance floor cannot be a whiteboard where every bee scribbles over yesterday’s dance. It has to be layered honeycomb cells, append-only, with authorship, timestamp, source, and reason on every important observation.
Who wrote this? When. Which page proves it. Was it approved? Which test validated it. What has changed since the last version. These are not nice-to-haves. When the price field goes null three months from now, the only way to diagnose the failure quickly is to read backwards through this trail and see which selector was used, which sample pages supported it, when it last passed, and what changed on the site.
In the Skills model, every skill that produces output writes to the blackboard with metadata, never overwrites. New observations append. Old versions stay. The blackboard becomes both memory and audit log, and that is what makes the rest of the system trustworthy.
Scene 4: Test the claim, not the confidence

Scene 4: test the claim, not the confidence
Agent systems can sound very confident while being completely wrong. This is especially dangerous in scraping, because plausible extraction is not the same as correct extraction.
A page might have three prices on it. Which one is the actual selling price? A product title might appear in the breadcrumb, the metadata, and the visible H1. Which one is correct? A field might exist in JSON-LD but be stale compared to the rendered page. Which source wins? An agent that says "I found the price" without proof is a bee dancing about a tree it never properly inspected.
This is why review gates matter, and why "another agent agreed" is the weakest possible form of review. The strongest judge is evidence.
A good review gate combines human review, visual comparison of extracted values against the rendered page, automated tests against fixture pages, local crawl runs, and field fill-rate checks. The motto should be: do not trust the dance, revisit the flower. If a skill says it found the price, show the page, show the extracted value, show the selector, show the test. Make the claim inspectable.
In practice, that means approval should happen at critical gates, not on every selector. Approve the schema before code generation begins. Approve expected values before fixtures get locked in. Approve crawl quality before deployment. Approve major repair strategies before rewriting large parts of the codebase. A human should not have to micromanage every CSS path. A human should approve the data contract and the material tradeoffs.
This is also where the bee metaphor sharpens against bad agent design. The loudest dance does not win. The dance with the strongest evidence wins. Popularity-weighted consensus across agents is a failure mode. Evidence-weighted consensus is the goal.
Scene 5: The builders build by testing

Scene 5: the builders build by testing
Once the spec is approved and the evidence is solid, code agents take over. This is where most agent systems go wrong by treating code generation as a creative writing task, handing the model the site and asking it to produce a spider. That approach feels fast at first and breaks within a week of running in production.
Code generation for scraping should be test-driven, not vibe-driven. The code phase needs a project bootstrap step, page object stubs, a fixture converter that turns sample pages into deterministic test inputs, selector analyzer workers that propose candidate selectors with confidence scores, a code synthesis step that generalizes across samples and prefers stable, explainable selectors, a test runner that becomes the actual heartbeat of the build, and a repair agent that fixes broken fields surgically rather than rewriting whole files.
The loop looks like this:
generate selector
-> run fixture tests
-> inspect failures
-> repair only the broken field
-> retest
The repair step is where many agent systems become destructive. A toddler with a hammer rewrites the whole project when one selector fails. A careful mechanic fixes the price method and leaves everything else alone. The orchestrator’s job here is to keep repair local and reversible.
Selector confidence is also worth treating as first-class metadata, not an afterthought. Not every field is equally reliable. A reasonable output from this phase looks something like:
title: high confidence
price: medium confidence
availability: fragile, fallback present
image: medium confidence, fallback needed
rating: low confidence, inconsistent across samples
This metadata is what lets the ops loop later know what to watch closely and what is probably fine. Fragile fields get heavier monitoring. High-confidence fields can be checked less aggressively. The whole system gets smarter about its own weakest points.
Underneath, the actual extraction can lean on Zyte API’s AI extraction for fields that have stable cross-site schemas, while custom code handles the site-specific oddities. The combination is usually faster and more durable than either approach alone.
Scene 6: The hive keeps running

Scene 6: the hive keeps running
A scraping system is not production-ready when it first passes tests. That is only the birth of the hive. The real test is what happens after deployment, because websites change. Layouts drift. Ban rates move. Response times shift. Fields disappear. Item counts drop. Pagination quietly breaks on page eleven instead of page ten. New templates appear under URLs that used to behave consistently.
Ops agents are the guard bees, maintenance bees, and drift watchers. They monitor item count, field fill rate, ban or block rate, response status distribution, average response time, data freshness, schema mismatches, and crawl success rate. The most important ops agent is the drift detector, because a spider can be syntactically healthy and semantically broken at the same time. It can run cleanly, return items, and still be silently dropping half the catalog or pulling empty prices.
When drift gets detected, the system should not panic and rewrite the project. It should route the signal back into the right loop. Field fill rate dropped means selector repair. Item count dropped means inspect pagination or category discovery. Ban rate spiked means inspect the crawl strategy, headers, session handling, or proxy and rendering setup, which is exactly what Zyte API’s unblocking is designed to handle automatically. HTML layout change means collect new samples and update selector candidates. Schema mismatch means trigger human review.
This is the difference between a generated spider and a living scraping system. The generated spider is born once and dies the first time the forest shifts. The living system senses the shift, identifies the loop that needs to act, and adapts.
Scene 7: One living, evolving organism

Scene 7: one living, evolving organism
The whole architecture should not be a straight line. It should be three connected loops.
The first is the discovery loop: explore, analyze, spec, review, improve the spec. This loop reduces uncertainty before any code gets written. The second is the build loop: generate code, test, repair, retest. This loop turns the approved spec into working extraction logic. The third is the operations loop: deploy, monitor, detect drift, repair, redeploy. This loop keeps the system alive as the website changes.
Together, these loops are the scraping organism. Not "plan, build, deploy." But "sense, decide, build, test, monitor, adapt." Each loop has its own bees, each bee has its own job, and the orchestrator routes attention between them as the state of the world changes.
The orchestrator deserves a separate note. In the bee version, it is not a queen barking orders. The queen does not actually command the swarm. In the software version, the orchestrator should not be a tyrant either. A weak orchestrator tries to be the smartest agent in the room, doing every inspection, writing every file, running every test. A strong orchestrator creates the conditions for specialists to do their jobs well. It senses state, routes attention, protects approval gates, decides what should happen next, knows when to stop, and knows when to ask for human input.
Its responsibility is flow, not heroics.
How this maps to Claude Skills in practice
When this architecture comes up in conversation with engineers who have not built with Skills yet, the question that follows is usually "but what does an agent actually look like in code?" The answer is simpler than it sounds.
Each agent role in the diagram is one Claude Skill. A skill is a folder, the folder has a SKILL.md describing when to use it and how to behave inside it, and optionally has scripts, templates, or reference docs the skill leans on. The examples that map directly to the scenes above look like this:
skills/
intake-spec-builder/ # Scene 1
detail-page-finder/ # Scene 2
page-downloader/ # Scene 2
site-explorer/ # Scene 2
link-classifier/ # Scene 2
schema-designer/ # Scene 3
fixture-builder/ # Scene 4
selector-analyzer/ # Scene 5
code-synthesizer/ # Scene 5
test-runner/ # Scene 5
repair-agent/ # Scene 5
drift-detector/ # Scene 6
cloud-deployer/ # Scene 6
The orchestrator itself is a higher-level skill that knows when to invoke each of the others, how to route state between them, and which gates need human approval. The blackboard is the shared filesystem they all read and write to.
Layered on top of Zyte API for fetching, unblocking, and AI-powered field extraction, and Scrapy Cloud for hosting and scheduling, you end up with something that genuinely fits the description of an AI-first scraping stack. The agents handle judgment, structure, and adaptation. The platform handles the heavy infrastructure underneath. The two together do not just produce a spider, they produce a system that keeps learning about its target.
Three questions to answer before you build one
When developers talk about agentic scraping, the same three field questions keep coming up, and they are the questions every scraping team should answer before building one of these systems. How much of the work do you want automated? What stays under human control? What happens when scraping fails?
The first question is about the scope of the colony. Automating everything sounds appealing until you remember that some decisions belong to humans, like deciding which sites to scrape in the first place, how to interpret ambiguous fields, or whether a drop in item count is real or a counting artifact. Decide where the automation stops before you build, not after the first surprise.
The second question is about gates. Where do humans need to approve, override, or be informed? Schema design is almost always one. Significant repair strategies usually are. Routine fixture updates and confidence-scored repairs probably are not. Get this wrong in either direction and the system either pushes too much to humans, which makes it slow, or hides too much from humans, which makes it risky.
The third question is the one most teams underweight. When the colony cannot extract a field, when the site changes shape, when a ban rate spikes, when an item count drops, what should the system do? The answer is rarely "stop everything." More often it is to fall back to the last known-good behavior, flag the anomaly, route the repair, and keep producing data within a known degraded state. That fallback behavior is part of the spec, not an afterthought.
Answering these three questions before you write code is most of the work. The bee colony architecture I just walked through is what implements the answers.
Closing thought
The diagrams that float around multi-agent orchestration end at the shared brain. Two or three agents, one shared memory, one human in the loop. They do not draw what happens when those agents hit a site that has just changed. What I have described in these seven scenes is what happens.
Multi-agent orchestration in web scraping is not about making AI agents look busy. It is about turning scraping from a brittle one-off coding exercise into an adaptive system that respects how messy real websites are. The bees in the diagrams are not decoration. They are a real architectural pattern, and once you start building this way, going back to single-shot scraping feels like watching one scout fly off into a storm and hoping for the best.
The bigger point underneath is that the role of the scraping developer is changing. The work that used to be selectors and retries is becoming the work of designing colonies. This is happening whether you opt in or not, and the developers learning to design colonies now will be the ones building the production scraping systems of the next few years. The good news is that the underlying stack to actually build these systems already exists. Zyte API handles fetching, unblocking, and AI extraction. Scrapy and Scrapy Cloud handle the framework and the hosting. Claude Skills handle the agent specialization. The pieces are on the table. The remaining work is design.
If you want to start, spin up a free Zyte API trial and build a small colony around one site. One scout, one builder, one test runner, one watcher. Pay attention to where it fails. The intuition you build over three months of running one of these systems is the intuition that will shape how production scraping gets done from here.





_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
