
The thing that finally pushed me to build a personal agent was not a coding task or a clever demo, it was the daily question of what to make for dinner, asked across a household where four people are somehow on four different diets, two parents are protecting overlapping work windows, a five-year-old needs to get to his classes, and a baby keeps his own schedule that respects nobody. My problem was never a shortage of ideas or tools. The problem was that all the context that actually held my days together, the meal plans and the appointments and the half-formed thoughts and the recipes I had saved and never found again, lived scattered across chat windows, browser tabs, voice notes, and my own overloaded head, with no reliable place to land and no way to come back to me at the moment I needed it.
What I ended up building is less a productivity bot and more a context layer around an ordinary life, and the single most useful thing I have learned from running it is that the model is not the setup. The loop around the model is the setup. This post walks through the actual architecture I run, layer by layer: the profiles and the three files that shape the agent, the skills that turn repeated work into reusable playbooks, the way I handle memory and the privacy boundary around it, and the model routing and web-data layer that let the whole thing reach the live web without losing the plot.
Why I started with the household, not the terminal
I came to agents through the least glamorous door there is. The spark was Tradclaw, an open-source household scaffold built by Claire Vo, which itself follows the pattern of Ryan Carson's clawchief. The premise is almost offensively simple, and it was the first framing of agents that actually described my life: most assistant examples are built around code, gadgets, and work, while almost none are built around the real domestic command center, which is family calendars, school triage, meal planning, pickup checks, homework logged from photos, and helper payments. So I started exactly there, with the most boring possible task, just the chores and the four calendars, because what I wanted before anything else was to lower the chaos and get into a rhythm.
That ordinary beginning taught me the thing the rest of the architecture is built to protect, which is continuity of context. Creativity is chaotic and ideas arrive everywhere except at a desk, in the middle of cooking, mid-sentence with a friend, while bathing the baby, and what an agent setup buys you is somewhere to put those threads down so you are not holding every open loop inside your own body. Everything below is in service of that.
The shape of the setup
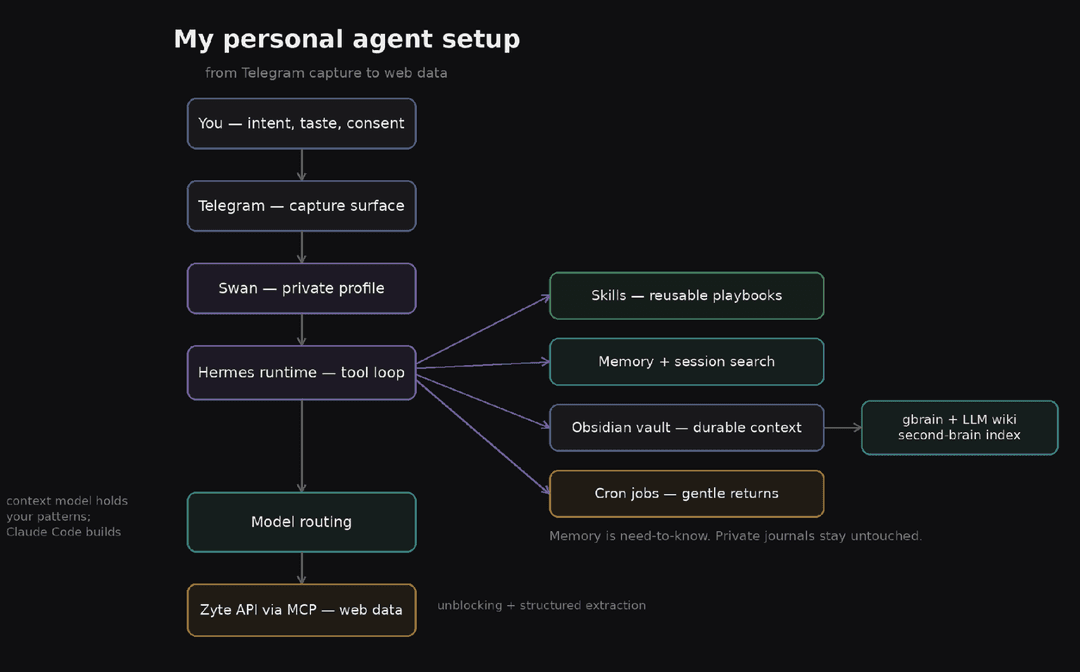
At a high level, the architecture is a small number of layers, each with one clear job, with me sitting at the top as the person who keeps taste, privacy, and the final say.
1me (intent, taste, consent)
2 |
3Telegram capture surface, available at the point of friction
4 |
5Swan (my private profile) orchestration, context, boundaries
6 |
7Hermes runtime tool loop: files, terminal, web, vision
8 |- skills reusable playbooks
9 |- memory \+ session search stable context, returnable threads
10 |- cron jobs gentle scheduled returns
11 |- Obsidian vault durable context and outputs
12 |
13model routing a context-holding model in the agent,
14 a building model (Claude Code) for real code
15 |
16Zyte API via MCP the web-data layer when the task touches the live webThe runtime is Hermes, an open-source agent framework that runs long on your own machine rather than living inside a single chat. Mine runs on a dedicated Mac Mini at home, which is its own honest design choice: people I trust run theirs sandboxed in Docker or an isolated virtual machine, and if you are going to give an agent real access to a file system, a sandbox is the more careful default. I interact with it almost entirely from Telegram, because the capture surface has to be wherever the friction is, while the command-line interface stays the cockpit for setup, logs, and deeper work. Telegram is the remote control. The CLI is the cockpit.
Profiles and the three files
The first real architectural decision is profiles. Hermes lets you run more than one, and that separation matters, because the agent that crunches household chores should not be the same persona that helps me think about DevRel content. The household profile started on the Mac Mini, and then I created my own private lane and named it Swan.
1hermes profile create swan
2hermes \--profile swan setup
3hermes \--profile swan
4
5Each profile is shaped by three files that almost every agent framework of this kind shares, and getting them right is most of the work:
6
7workspace/
8 user.md who I am, how I work, what I care about
9 soul.md the agent's stance, boundaries, and non-negotiables
10 memory.md compact, stable facts worth carrying across sessions
11 skills/ reusable playbooks
12 memory/ longer-term notes the agent maintainsThe strongest advice I can give about these files is to resist the temptation to pour your entire self into them on day one. The thing that worked for me was going slowly, reflecting on how I actually process and function, and telling the agent that gradually, so the persona had room to adapt rather than being frozen on the first afternoon. I deliberately keep a small amount of doubt and a self-correcting loop built into soul.md, because it honestly unsettles me when an agent is too sure of itself, and I would rather it stay a little open and questioning than become a confident mirror that only reflects what I already believe. This is also where the non-negotiables live, the clear lines about what it may never touch, which I will come back to under memory.
Skills, and how the agent writes its own
Once profiles and files are in place, skills are where the setup starts to compound. A skill is a reusable playbook: when to use it, the steps to follow, the mistakes to avoid, and what a good output looks like. The reason skills matter more than prompts is that most agent work is not one cinematic task, it is the same small workflows repeated, so anything I guide the agent through twice becomes a candidate for a skill, and each skill should do one thing well.
A few of mine, to make this concrete. The /background skill lets a task run in the background while I keep talking, which for a jumpy thinker is the difference between staying in flow and losing the thread. A /last-30-days style skill pulls a structured report of what happened in a given domain over the last month, which I lean on constantly for keeping up with the web-scraping space. And my favorite small one started as pure household need: I am a serious recipe hoarder, so I built a skill that takes a link and pulls the ingredients and method into a clean, searchable database, and the interesting part is that the agent worked out the retrieval mechanics for it largely on its own when I asked it to go figure it out and teach me.
That self-authoring behavior points at the best practice I would actually pass on. When you find a skill you like in someone's public repository, the move is not to download it blindly. You point your agent at the repository and ask it to recreate the skill in your context, using what it already knows about how you work, and then you review the result. Hermes does a version of this automatically, noticing the tasks you repeat and proposing skills from your lived patterns. I wrote more about where this fits against other approaches in Claude skills, MCP, or Web Scraping Copilot: which should you choose, and the short version of the mental model there is brain, hands, and manual: skills are the manual you hand the brain.
One caution belongs right here, because it is a real security boundary and not a footnote. Pointing an agent at third-party skills is a genuine prompt-injection risk, since a skill is instructions your agent will follow, so audit anything before you let it run, especially when the agent has access to a whole machine.
Memory, Obsidian, and the privacy boundary
Memory is the most powerful part of an agent setup and the easiest to misuse. I do not want Swan to remember everything, I want her to remember only what reduces repeated steering: stable preferences, project conventions, the places I push back, and things I have explicitly corrected. Memory should reduce repeated steering, not flatten a living person into a fixed file. Treated carelessly it becomes a quiet yes-man, confidently feeding you back the biases you handed it, which is exactly the failure I am trying to design out.
The durable context lives in Obsidian, and this is where the hardest boundary in my whole setup sits. My vault holds years of private journals, and those are not for any agent, so I told Swan plainly to never touch them and to keep her own work in a separate folder inside the same vault, with everything she generates landing there and nowhere near my words. On top of that vault I run Garry Tan's gbrain, an indexing skill built in the spirit of Andrej Karpathy's LLM wiki, to build a navigable second brain across my notes, with guardrails and a priority map so the agent knows what matters and what is off limits. gbrain does the quiet, unglamorous work of holding all of that context so I do not have to maintain the index by hand, and it has carried more of this setup than almost anything else. The pattern I keep coming back to is simple: chat is for movement, Obsidian is for continuity, and a chat answer that never lands in a durable note is an incomplete workflow.
Web data: model routing and the Zyte layer
Two routing decisions make the setup actually usable. The first is between models. Inside Hermes I run a context-holding model that carries my patterns, my files, and the history of how I like things done, and I do my thinking and prompt engineering there. When it is time to build something real, a demo or a working spider, I hand that context to Claude Code, which is where the serious code gets written. I will not replace the agent with the coding tool or the other way round, because they are different jobs: one holds the continuity of my lived context, the other builds.
The second routing decision is for the live web, and this is where a generic agent quietly falls down. An agent can fetch a page and still not understand what it got, whether the fields it needs are missing, or whether the HTML is just a shell, and the failure mode that worries me most is the confident, complete-looking answer that has silently dropped half of what it could not reach. I learned this on a small personal experiment, pointing the setup at a public recipe creator's archive to build that recipe database, working only with publicly reachable content and treating throttling and partial access as part of the evidence rather than something to bypass. It sounded trivial and it was not, because some of the data lived in captions, some pointed off to other pages, and some was simply incomplete, which taught me that reaching a page is not the same as extraction, and extraction is not the same as a trustworthy dataset.
That is exactly the gap the Zyte layer closes for me. I gave the agent access to Zyte API through a community Model Context Protocol (MCP) server, so that whenever a task needs the web it routes through infrastructure built for unblocking and structured extraction instead of a raw fetch that gets blocked or returns a blank shell. In practice the agent reaches for it on its own, and a minimal call against a safe target looks like this:
1import requests
2
3response \= requests.post(
4 "https://api.zyte.com/v1/extract",
5 auth=("YOUR\_API\_KEY", ""),
6 json={
7 "url": "https://books.toscrape.com/",
8 "httpResponseBody": True,
9 "product": True,
10 },
11)
12
13data = response.json()For anything beyond single-page extraction, the same engine is what powers production spiders, and the broader shift here, from a plain-English data need to a reliable, monitored pipeline, is the through-line I find most interesting about where agents and web data are heading, which the team laid out well in AI and the web: what 2025 changed and what comes next.
Start with one broken thing
If you want to build something like this, I would not tell you to copy my whole stack. The discipline underneath all of it is stubbornly analog, because you cannot tell an agent what you want until you know what you want, and these tools meet you exactly where you are. The more sophisticated my setup got, the more seriously I took the daily sit-down with pen and paper, asking what I actually want this week and how I actually function, and the truest description I have of the practice is that you tend the agent like a garden, slowly, paying attention to your own process as you go, and you grow alongside it rather than installing it fully formed.
So pick the one workflow that keeps leaking out of your day, the single recurring loss that costs you the most mental weight, and start there. Build that one thing, let it settle, then reach for the next. The agent takes the shape of how you work, not the other way around, and the part that stays yours, the taste, the privacy, and the final say, is the part worth protecting most.
If you want to give the web-data layer a try in your own setup, you can start with a free Zyte API account and point your agent at it.





_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
