Web Scraping at Scale
Anita Clarke
7 min read ·

1. A plan is a pathway to success
Web scraping at scale requires a plan to be successful. You need to:
define the business case,
define the type of data needed to support the business case,
evaluate your current capabilities, and
estimate your costs (full cost accounting for developers and infrastructure).
Define the business case
A rigorous business case is critical to an effective plan. It gives a web scraping project a clear objective, timeline and a way to measure progress and success. Understanding the problem with a strong business case helps identify what data is needed to be successful.
Some business cases that are best supported with web scraping at scale include:
competitive analysis,
price optimization,
real-time market trends,
lead generation,
customer sentiment analysis,
academic research,
supply chain and inventory management,
artificial intelligence training datasets,
benchmarking and performance analysis,
compliance monitoring, and
trend analysis.
Define your data needs
It might be easy to extract all the data from a domain and worry about what’s necessary afterwards, but that strategy is costing you money, from development costs to storage. For example, do you need all that data? It’s best to be precise as costs can spiral out of control when applied to hundreds of sites. You only want to extract the data needed to support your business case so you’re not paying for the crawling, extraction, post-processing and storage of data you don’t need.
⚡Tip 1: Help identify your data needs with Zyte standard data schemas.
Zyte’s standard data schemas are a great place to start identifying the kind of data you can and should collect. They’re based on the work from W3C’s Schema.org Community Group whose mission is to create, maintain, and promote schemas for structured data on the Internet. We’ve designed these for web scraping and support the most common item types and their most common properties.
Evaluate current capabilities
Do you have an in-house web scraping team? Do you need one?
Taking stock of the team’s capabilities lets you see what needs to be improved or built upon to scale successfully. This evaluation can help identify weaknesses in resources, expertise, tooling, infrastructure, quality assurance and legal compliance.
Another important part of evaluating your current capabilities is thinking about whether you need to build or buy web scraping services. There are many businesses involved in web data, like Zyte Data, that can handle all your web data needs or supplement the existing team. We’ll dive deeper into these questions in section 6. The In-house vs outsourced question
⚡Tip 2: Use the Web Scraping Maturity Model self-assessment
Zyte has over 14 years of experience in web scraping and during that time we’ve identified patterns that positively impact web scraping projects. We created a model of these patterns by researching the web scraping approaches, gaps and successes of over 40 different companies that power their businesses with web data. Four dimensions make up the backbone of the model:
Planning and design
Compliance
Building Quality
Scaling and Maintaining
The Web Scraping Maturity Model serves as a formal playbook and benchmarking framework for teams, allowing them to evaluate how they are performing against industry counterparts. Taking the assessment highlights areas to improve a team’s ability to assess their web scraping projects for maturity, reliability, and scalability.
Your codebase should be reusable and portable
Scaling with an in-house team means a larger and more complex codebase. Your team needs to establish development practices to use modularity and standardization. These reusable components can be used across all scraping projects saving the development team significant time and effort.
Thankfully there are several web scraping frameworks available and most of the industry has adopted Python as the programming language of choice. When we started scraping at Zyte there weren’t any frameworks, so we created one called Scrapy — it’s the most popular web scraping framework.
When operating at scale, you might encounter different environments when deploying your web crawlers and extractors. Ensuring your codebase is portable helps to simplify deployment and maintenance and reduces development time needed.
Estimate the costs
The business case is solid, now it’s time to estimate how much it’s going to cost. Web scraping at scale impact the following costs:
Increased resource investment: To scale you need increased investments in hardware, software and people. There are probably many other projects in your business that need investment also, so you’ll have to decide if investing in web scraping resources offers a clear return on investment.
Increased operational costs: Scaling web scraping means more management and operational oversight. This could be at the expense of other projects that need those resources also.
Increased legal and compliance costs: Ensuring compliance with the various and complex international laws is vital as operating at scale makes you a target for legal scrutiny. Your legal team will have to dedicate more of their time to this endeavor, leaving less time for other legal and compliance needs across the company.
Good cost estimates come from good inputs. For those of you using vendors, your costs are simpler and way more predictable. For those of you managing an in-house team, you need to know how much effort (man hours and operating costs) goes into a web scraping project.
An easy way to deal with the complexity of creating estimates is to use low, medium, and high categories to define a website’s complexity. Here’s a simple matrix you can use (or modify) to define the complexity of your past projects. By defining the complexity of past projects, you can create benchmarks for each category. Those category benchmarks can be used to estimate future projects. The biggest factors impacting complexity in descending order are the anti-bot deployed, extraction logic complexity and crawling logic complexity. The factors are weighted to account for importance. To determine the complexity of a project, take a look at the factors and use 1 to 5 to rank each of them from easy to difficult.
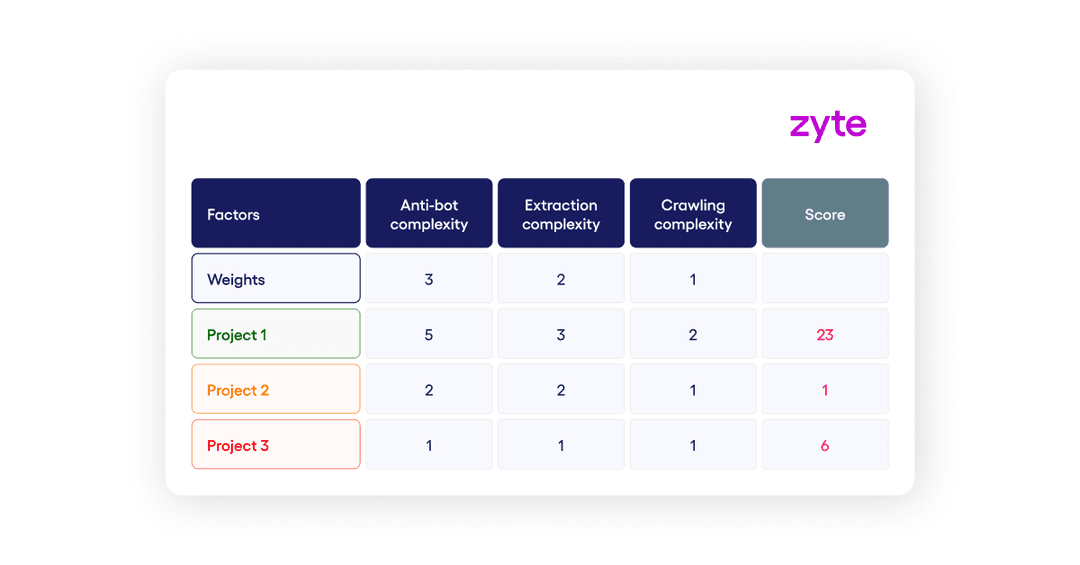
When scoring your projects you can categorize them using the scoring system based on the matrix:
Your project has low complexity if scores between 0 and 12.
Your project has medium complexity if scores between 12 and 23.
Your project has high complexity if scores between 23 and 30.
Now for each project, you can use the following table to record the costs and man hours:
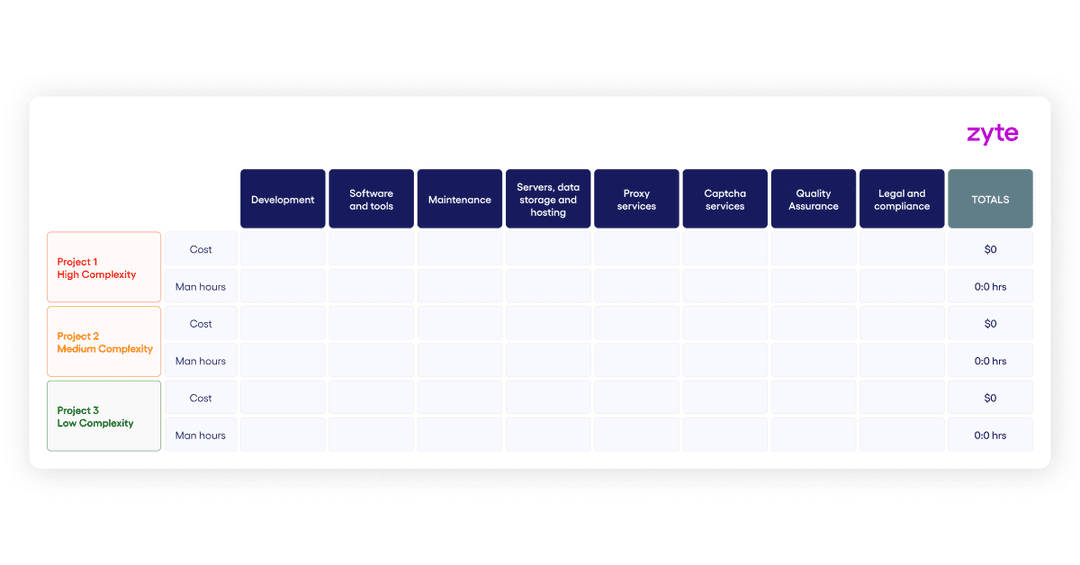
Sometimes it’s good to look at operation costs at a more granular level by determining the cost per record saved or cost per request in each category. Just take the total cost and divide the number of records or requests in a project.
Now you have a baseline on how much it costs in each category, you can apply it to new project estimates. You’ll need to identify the category of the target website and use the corresponding baseline to estimate costs. As you complete more projects, you can refine the estimation process to make it more accurate.
Scaling from scratch and need help deciding if you want to develop an in-house team or outsource all web scraping projects to a third party? We’ll unpack the different options in section 6. The In-house vs outsourced question.
Continue to the next chapter 2. Get serious about legal compliance
More learn articles
Keep learning
 Use case
Use caseWhat is a residential proxy?
Learn what residential proxies are, how they compare to datacenter proxies, and why modern web scraping needs more than IP diversity.
10 min read
 Use case
Use caseHow much do rotating proxies cost?
Learn how much rotating proxies cost, what affects pricing, and why total web scraping costs often go beyond proxy subscriptions.
10 min read
Use caseHow do rotating proxies work?
Learn how rotating proxies work, when to use them for web scraping, and why IP rotation alone is not enough for reliable data access.
10 min read




_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
