
This is the first article in a two-part series. In this part we will get clear on what an agent harness actually is, why it has quietly become the thing that separates an AI agent that works from one that only seems to, and what the pieces inside it are. In the second part we will put all of it to work and build a web data extraction agent from scratch.
Let me start with the claim that reframed how I think about this. Recently, Microsoft's chief executive, Satya Nadella, published an essay arguing that a frontier without an ecosystem is not stable, and his core point was that the real opportunity is not in picking the best model but in building a learning loop on top of models. The model, in other words, is increasingly something you can swap out, it’s becoming a commodity and the durable value lives in the system you build around it.
LangChain put a number on the same idea from the engineering side: in their writeup on harness engineering they took one coding model, changed nothing about the model itself, improved only the scaffolding around it, and watched its score on the Terminal Bench 2.0 benchmark climb from 52.8% to 66.5%, moving from somewhere around 30th place into the top five. Same model, very different agent.
That scaffolding is the harness, and harness engineering is the craft of building it well.
What a harness actually is
Here is the thing that trips people up: a language model, on its own, is almost helpless. It does exactly one thing, which is to take some text and produce some more text, once, with no memory of the last time you called it and no way to act in the world. It cannot open a web page, cannot run code, cannot remember what it figured out on a previous run, and cannot check whether the answer it just gave you is correct.
The harness is everything you wrap around that model to turn it into something that can actually get a job done over many steps. If the model is a brilliant mind sitting in a sensory deprivation tank, the harness is the body, the senses, the notebook, and the to-do list. The single most useful way to hold this in your head is that the model supplies the intelligence and the harness supplies the capabilities. Same brain, different cage, completely different agent.
The clearest way to see this is to look at Anthropic's own products. Claude Code, the claude.ai chat app, Claude in Chrome, and Claude in Slack can all be powered by the very same model, something like Opus or Sonnet, and yet each one behaves like a different assistant entirely, because each wraps that shared model in its own harness with its own system prompt and its own set of tools. Claude Code is told to behave like a software engineer and handed tools to run shell commands and edit files, Claude in Chrome is given the ability to drive your browser, and Claude in Slack is set up to read and reply inside your channels and threads. The model underneath can be identical. The agent you experience is not.
In a nutshell an AI agent is nothing but : A model + A harness
Why you should care
You should care because the harness is the part you control. You are probably not training a frontier model, but you have complete freedom over everything around it, and that is exactly where Nadella's argument and LangChain's number meet. For any given model, the harness decides how much of that model's intelligence you actually capture, and the gap between a lazy harness and a thoughtful one is not small, it is the difference between 30th place and the top five on the very same model.
It is also where three things you care about actually live. Reliability lives there, because a good harness checks the work instead of trusting it. Cost lives there, because a good harness is careful about what it feeds the model. And your competitive moat lives there too, because, as Nadella points out, anyone can rent the same model, but nobody can rent the loop of workflows, checks, and accumulated knowledge you have built around it. The model is the commodity, and the harness is the part that compounds.
The pieces inside a harness
So what is actually inside one? It looks like a lot of moving parts at first, but it really comes down to a handful of components, each with a single job, arranged around the model in the middle.

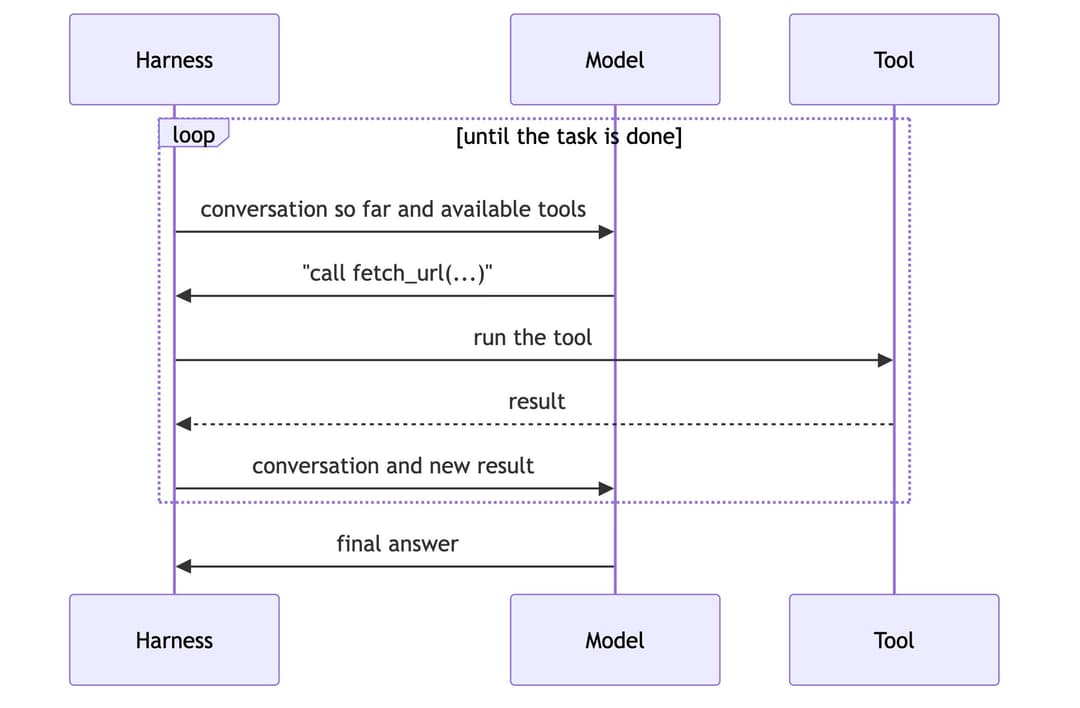
The loop is the engine that everything else plugs into. On its own the model answers once and stops, so the harness wraps it in a loop where it sends the model the conversation so far along with the tools it is allowed to use, the model either answers or asks to use a tool, the harness runs that tool and feeds the result back, and round it goes until the work is done.
The system prompt is the agent's operating manual, the standing instructions it reads on every single turn, covering who it is, how it should behave, and how to use its tools. The published claude.ai system prompt is a good public example of just how much personality and policy lives in this one block of text.
Tools are the agent's hands. The model cannot touch the world directly, so tools are how it acts, whether that means reading a file, running a command, fetching a page, or calling an API, and the set of tools you hand an agent is most of what decides what kind of agent it becomes.
Context management is the harness deciding what to put in front of the model on each turn, because the model can only read so much at once, and because it is stateless the harness has to re-send the whole conversation every time. As that conversation grows the harness has to summarize, trim, or offload parts of it to stay within the limit.
Memory is the state that survives beyond a single conversation. Where context management deals with one session, memory is the agent writing things to a durable store, a file or a database, that it can read back next time so it does not start from scratch on every run.
Sub-agents are how an agent delegates. Instead of doing everything inside one long, messy conversation, an orchestrator spawns child agents, each with its own fresh context, to handle a piece of the work and report back only the clean result, which keeps the main agent focused and lets the work run in parallel, the same multi-agent orchestration I lean on in my own agentic coding setup.
Planning and verification are how the agent decides what to do next and, just as importantly, how it knows when it is actually finished. Left to themselves, models will happily declare a job done when it is not, so a good harness makes the agent plan its steps and then checks the result against some objective standard before it is allowed to stop.
A quick word on guardrails
One more idea worth planting before we build anything. Around that core you will often find smaller interventions, a check that stops the agent looping forever, a budget limit, a nudge to verify before finishing, and these are usually called middleware or hooks because they run before or after each step of the loop. The LangChain team made a point worth holding onto, which is that many of these are interim guardrails that engineer around the weaknesses of today's models and will quietly become unnecessary as models improve. Since I am always trying new models in my own setup, I find it useful to treat some of my harness as scaffolding. I will happily delete the day a model no longer needs it, which is a good way to tell the permanent parts from the temporary patches.
What comes next
That is the whole map: a model in the middle, wrapped by a loop, a prompt, tools, context management, memory, sub-agents, and a verification step, with a few guardrails around the edges. None of it is exotic once you can name the pieces. In the second part of this series we will stop describing and start building, taking every one of these components and turning it into a working web data extraction agent, the kind of thing you would actually point at a defended e-commerce site to pull clean, structured data from. That is where the ideas get concrete, and where the Zyte API tools we lean on come in.





_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
