Zyte Blog
Field notes from the world of data extraction.
Articles, interviews and analysis on how data is gathered, used and fought over — written by the people closest to it.
Browse
Hot topics
Latest
What we've been publishing

I joined the Real Python podcast to talk harnesses and Scrapy
I was recently a guest on the Real Python podcast where host Christopher Bailey opened with the question that has been following me around all year: which matters more, the model or the harness around it? Let's look into it.

Building maintainable spiders with scrapy-poet
Separating your extract and parsing logic out help increase the maintainability and extensibility of your projects, and scrapy-poet makes it easy.

Modern Scrapy for experienced developers: A new series
How to create production ready Scrapy projects to scrape the modern web. In this article we start the process of creating our spider, look at settings, and build a pipeline to help keep our data quality high.

A guide to Scrapy item types
Scrapy supports multiple item types, but which should you use, and why.

New Zyte add-ons: Agent Skills, Codex, GitHub and more updates
A host of additions to Zyte’s agentic scraping toolbelt helps developers go from prompt to working spider code and beyond.

Podcast Ep08 - Scrapy, Python and mushroom soup
Scrapy's core handles crawling well and deliberately leaves almost everything else out: no bundled browser, no opinion about how you shape your data, no built-in answer for every anti-bot wrinkle. What it gives you instead is a clean way to add those things at the edges, exactly when you need them and never before.

Five reasons to attend this year’s Extract Summit
In its eighth year, Extract Summit is again shaping up to be the web data industry's premier gathering.

The missing middle ground in scrapy-playwright just got filled
You can now choose which Python browser library you want to use with scrapy-playwright. I go through why this is a huge deal for the right scraping demographic.

Harness Engineering #3- Headless mode: the minimal agent harness
What's the smallest harness that still works? Turns out it's already sitting inside almost every coding agent you have installed — headless mode: same loop, tools, and reasoning as the interactive agent, minus the human in the chair. We point it at a web page and pull clean, structured data out the other end in about ten lines.

Claude Fable 5 is the new best model for writing scrapers
We ran nine models, including the new GPT-5.6, through our Zyte Scraping Code Benchmark. Claude Fable 5 puts Sol and others in the shade - but it’s pricey, and the best extraction code still depends on the best infrastructure.

GPT-5.6, Fable 5, and GLM-5.2 entered a bar “crawl” and got hit by The Rate Limit
When OpenAI shipped GPT-5.6 and Anthropic's Fable 5 was sitting at the top of the price list, my question was not "which one wins a leaderboard." It was the one I actually pay for: for the scraping I do, how much model do I need to buy?
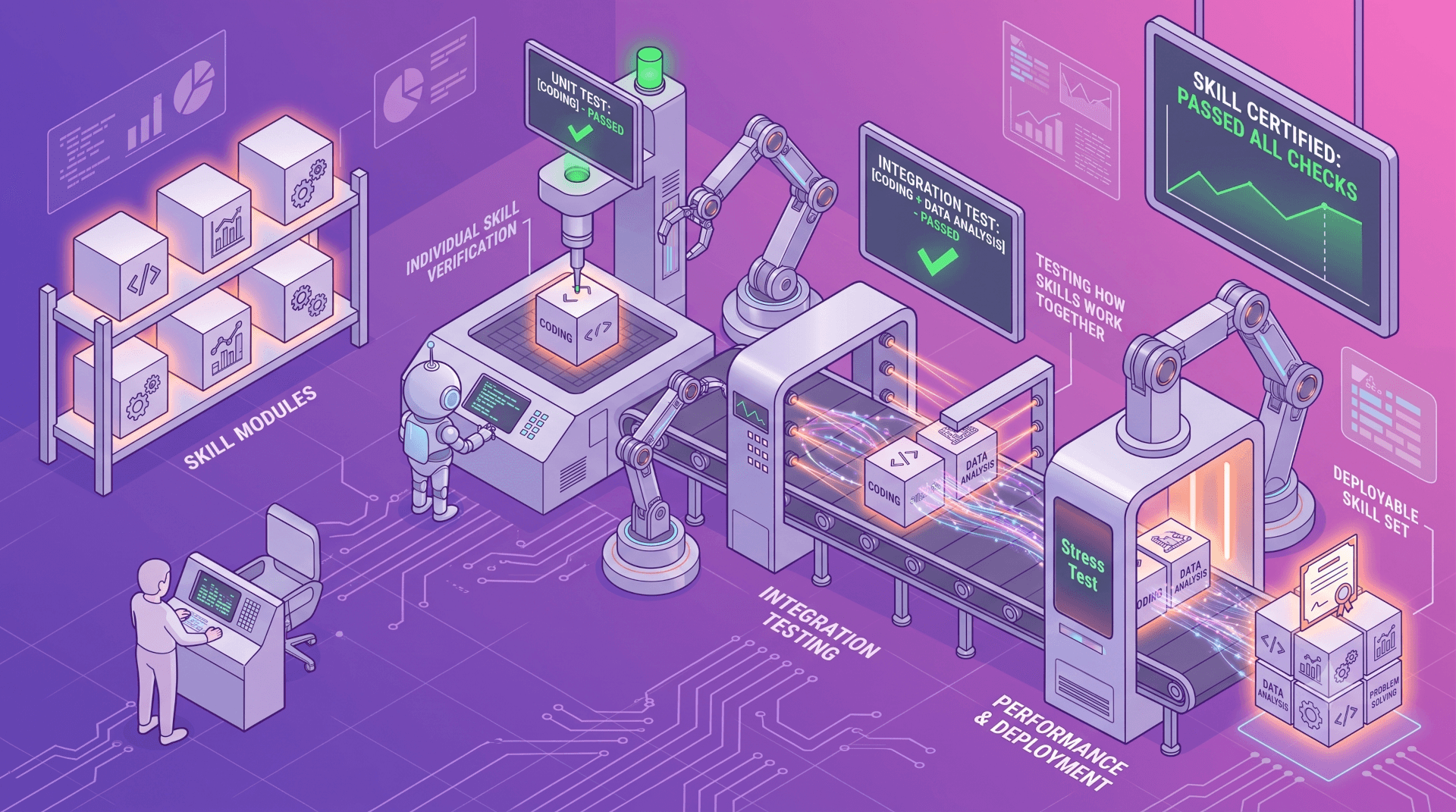
Treat your AI skills like software, starting with evals
Most AI skills are never tested — and it shows. Here's how Zyte evaluates scraping skills like real software, catching failures demos miss.
Zyte YouTube
Watch & learn

Video · Zyte YouTube
AI generated these Scrapy projects - why I won't ship them
July 7, 2026

Video · Zyte YouTube
Screenshot webpages with this Claude Skill and Zyte API
March 6, 2026

Video · Zyte YouTube
0% Hallucination? RAG + Web Scraping (Step-by-Step)
March 5, 2026

Video · Zyte YouTube
Generate HTML Parsing code the right way with Scrapy & Web Scraping Copilot
February 23, 2026

Video · Zyte YouTube
Zyte API Sessions - flexible cookie management maintaining control
February 6, 2026
Events & community
Where Zyte shows up
 7–8 Oct 2026
7–8 Oct 2026Extract Summit 2026 — Austin, TX
In-person conference · Austin, TX
 10–11 Nov 2026
10–11 Nov 2026Extract Summit 2026 — Dublin
In-person conference · Dublin, Ireland
 On demand
On demand2026 Web Scraping Industry Report by Zyte
Webinar · On demand
 On demand
On demandExtract Summit 2025 — Dublin
In-person conference · Dublin, Ireland




_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
