The New Guide to Web Scraping at Scale_One_Page
20 min read ·
Web data, when extracted, refined and put to use creates new pathways to opportunity and profitability. Market research, customer acquisition, price intelligence, risk management, product development and sentiment analysis, to name a few use cases, are all powered by public web data. Businesses that tap into timely and accurate web data make informed decisions and customer insights, improve operational efficiency and increase their competitive advantage.
This probably isn’t new to you but even the most experienced business owners often overlook exploring opportunities outside of their internal data repositories. Gathering impactful web data quickly and cost-effectively using modern web scraping technology is possible. Building robust web data extraction for your organization at scale means that:
new sources of web data can be added easily,
costs of adding new sources of data can be estimated accurately, and
new business requirements and market changes can be adjusted to quickly.
You’re probably already gathering data from a handful of websites and it’s been easy so far. But as your business grows, so will your need for public web data. Don't be lulled into a false sense of security because the easy experience doesn’t translate at scale. The challenges of scaling web scraping are underestimated. Increased costs when scraping a handful of websites don’t affect your bottom line much. However, if you’re operating at scale, and extracting from 1,000 websites, those costs balloon to a much larger problem. Minimizing costs is a key feature of scaling web scraping in an effective way.
This whitepaper will walk you through what to consider when scaling your web scraping efforts from planning and design, legal compliance, crawling and extracting, artificial intelligence (AI) and quality assurance. We’ll also examine whether you should scale your web scraping operation by building in-house, taking a hybrid approach, or completely outsourcing data extraction to a third-party vendor.

1. A plan is a pathway to success
Web scraping at scale requires a plan to be successful. You need to:
define the business case,
define the type of data needed to support the business case,
evaluate your current capabilities, and
estimate your costs (full cost accounting for developers and infrastructure).
Define the business case
A rigorous business case is critical to an effective plan. It gives a web scraping project a clear objective, timeline and a way to measure progress and success. Understanding the problem with a strong business case helps identify what data is needed to be successful.
Some business cases that are best supported with web scraping:
competitive analysis,
price optimization,
real-time market trends,
lead generation,
customer sentiment analysis,
academic research,
supply chain and inventory management,
artificial intelligence training datasets,
benchmarking and performance analysis,
compliance monitoring, and
trend analysis.
Define your data needs
It might be easy to extract all the data from a domain and worry about what’s necessary afterwards, but that strategy is costing you money, from development costs to storage. For example, do you need all that data? It’s best to be precise as costs can spiral out of control when applied to hundreds of sites. You only want to extract the data needed to support your business case so you’re not paying for the crawling, extraction, post-processing and storage of data you don’t need.
⚡Tip 1: Help identify your data needs with Zyte standard data schemas.
Zyte’s standard data schemas are a great place to start identifying the kind of data you can and should collect. They’re based on the work from W3C’s Schema.org Community Group whose mission is to create, maintain, and promote schemas for structured data on the Internet. We’ve designed these for web scraping and support the most common item types and their most common properties.
Evaluate current capabilities
Do you have an in-house web scraping team? Do you need one?
Taking stock of the team’s capabilities lets you see what needs to be improved or built upon to scale successfully. This evaluation can help identify weaknesses in resources, expertise, tooling, infrastructure, quality assurance and legal compliance.
Another important part of evaluating your current capabilities is thinking about whether you need to build or buy web scraping services. There are many businesses involved in web data, like Zyte Data, that can handle all your web data needs or supplement the existing team. We’ll dive deeper into these questions in section 6. The In-house vs outsourced question
⚡Tip 2: Use the Web Scraping Maturity Model self-assessment
Zyte has over 14 years of experience in web scraping and during that time we’ve identified patterns that positively impact web scraping projects. We created a model of these patterns by researching the web scraping approaches, gaps and successes of over 40 different companies that power their businesses with web data. Four dimensions make up the backbone of the model:
Planning and design
Compliance
Building Quality
Scaling and Maintaining
The Web Scraping Maturity Model serves as a formal playbook and benchmarking framework for teams, allowing them to evaluate how they are performing against industry counterparts. Taking the assessment highlights areas to improve a team’s ability to assess their web scraping projects for maturity, reliability, and scalability.
Your codebase should be reusable and portable
Scaling with an in-house team means a larger and more complex codebase. Your team needs to establish development practices to use modularity and standardization. These reusable components can be used across all scraping projects saving the development team significant time and effort.
Thankfully there are several web scraping frameworks available and most of the industry has adopted Python as the programming language of choice. When we started scraping at Zyte there weren’t any frameworks, so we created one called Scrapy — it’s the most popular web scraping framework.
When operating at scale, you might encounter different environments when deploying your web crawlers and extractors. Ensuring your codebase is portable helps to simplify deployment and maintenance and reduces development time needed.
Estimate the costs
The business case is solid, now it’s time to estimate how much it’s going to cost. Web scraping at scale impact the following costs:
Increased resource investment: To scale you need increased investments in hardware, software and people. There are probably many other projects in your business that need investment also, so you’ll have to decide if investing in web scraping resources offers a clear return on investment.
Increased operational costs: Scaling web scraping means more management and operational oversight. This could be at the expense of other projects that need those resources also.
Increased legal and compliance costs: Ensuring compliance with the various and complex international laws is vital as operating at scale makes you a target for legal scrutiny. Your legal team will have to dedicate more of their time to this endeavor, leaving less time for other legal and compliance needs across the company.
Good cost estimates come from good inputs. For those of you using vendors, your costs are simpler and way more predictable. For those of you managing an in-house team, you need to know how much effort (man hours and operating costs) goes into a web scraping project.
An easy way to deal with the complexity of creating estimates is to use low, medium, and high categories to define a website’s complexity. Here’s a simple matrix you can use (or modify) to define the complexity of your past projects. By defining the complexity of past projects, you can create benchmarks for each category. Those category benchmarks can be used to estimate future projects. The biggest factors impacting complexity in descending order are the anti-bot deployed, extraction logic complexity and crawling logic complexity. The factors are weighted to account for importance. To determine the complexity of a project, take a look at the factors and use 1 to 5 to rank each of them from easy to difficult.
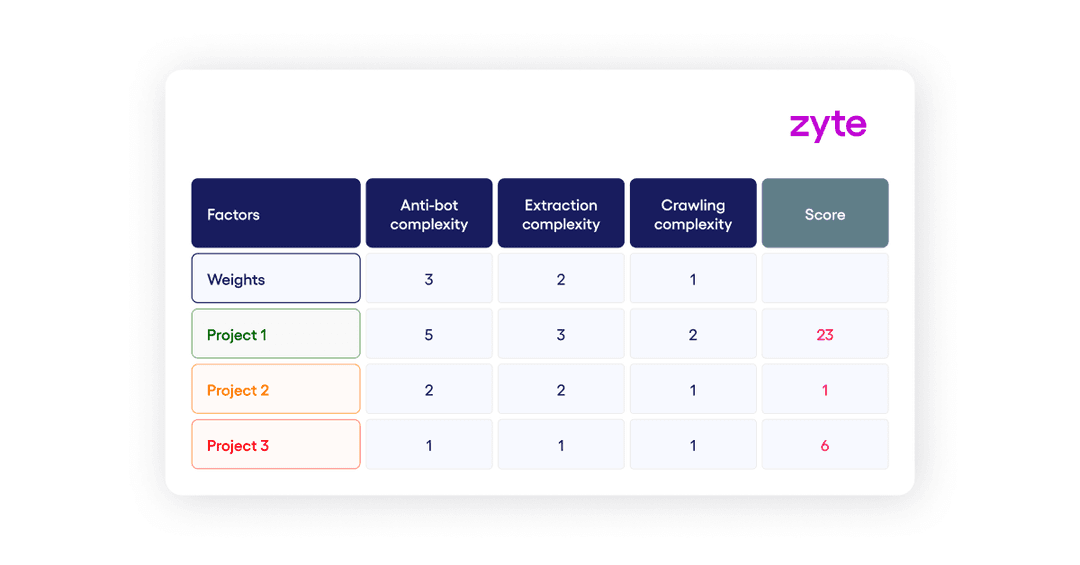
When scoring your projects you can categorize them using the scoring system based on the matrix:
Your project has low complexity if scores between 0 and 12.
Your project has medium complexity if scores between 12 and 23.
Your project has high complexity if scores between 23 and 30.
Now for each project, you can use the following table to record the costs and man hours:
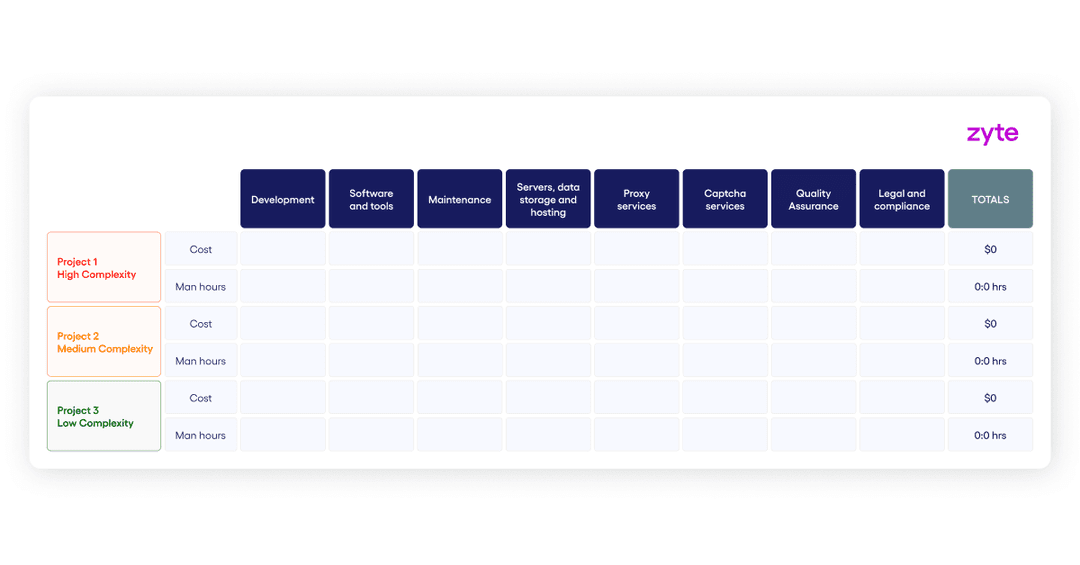
Sometimes it’s good to look at operation costs at a more granular level by determining the cost per record saved or cost per request in each category. Just take the total cost and divide the number of records or requests in a project.
Now you have a baseline on how much it costs in each category, you can apply it to new project estimates. You’ll need to identify the category of the target website and use the corresponding baseline to estimate costs. As you complete more projects, you can refine the estimation process to make it more accurate.
Scaling from scratch and need help deciding if you want to develop an in-house team or outsource all web scraping projects to a third party? We’ll unpack the different options in section 6. The In-house vs outsourced question.

2. Get serious about legal compliance
Operating legal and ethical web scraping projects at scale needs legal oversight by lawyers with a specialization in web scraping. There are a number of risks, including compliance with personal data regulations, copyright law, contract law and more. Some of these issues are also the subject of litigation — for a recent update, see our article on the Meta v Bright Data case.

Generative Artificial Intelligence (AI) systems and large language models (LLMs) have a host of case law and regulations pending. Your legal team should be keeping on top of these developments to help navigate these laws. Case law is changing rapidly in this space and will only increase as other countries pass AI legislation.
⚡Tip 3 : Use Zyte’s Compliant Web Scraping checklist against your projects
Zyte’s Compliant Web Scraping checklist can help you determine if web scraping projects are being performed in a legally compliant and ethical manner. Because there are no specific web scraping regulations, there’s a labyrinth of laws that one must navigate before embarking on a web scraping project. The checklist highlights the key areas to look out for:
If you answer “Yes” to any of the points above, the checklist outlines the next steps to take. If you answer “No” to any of these points then the project is likely lower risk. Remember to consult your own lawyer to ensure compliance in either case.

3. The quality of your data is of utmost importance
Bad data can be worse than NO data.
Making sure your web data is trustworthy at scale is incredibly important, so one of the defining success factors is a comprehensive quality assurance (QA) process. The best web scraping tech stack in the world is useless if data integrity can’t be trusted.
At scale there should be comprehensive plans that incorporate fully automated data quality and monitoring strategies. Incorrect data can have far reaching impacts on upstream and downstream systems consuming the data.
QA happens at several parts of the data stack:
testing and monitoring of the spiders and tech to ensure technical operation is maintained and data flows are as expected, and
testing of the data itself from deduplication, checking error rates, data quality, etc.
At the smaller scale, monitoring and QA sometimes can be checked manually by “eyeballing the data” or manually auditing data, especially if it’s infrequent and small amounts. But what happens when you collect 10 million product prices or 100 million real estate listings? You must have specialized tools and resources to evaluate and monitor quality. Like your development team, QA has associated costs, delivery time implications, setup costs, etc.
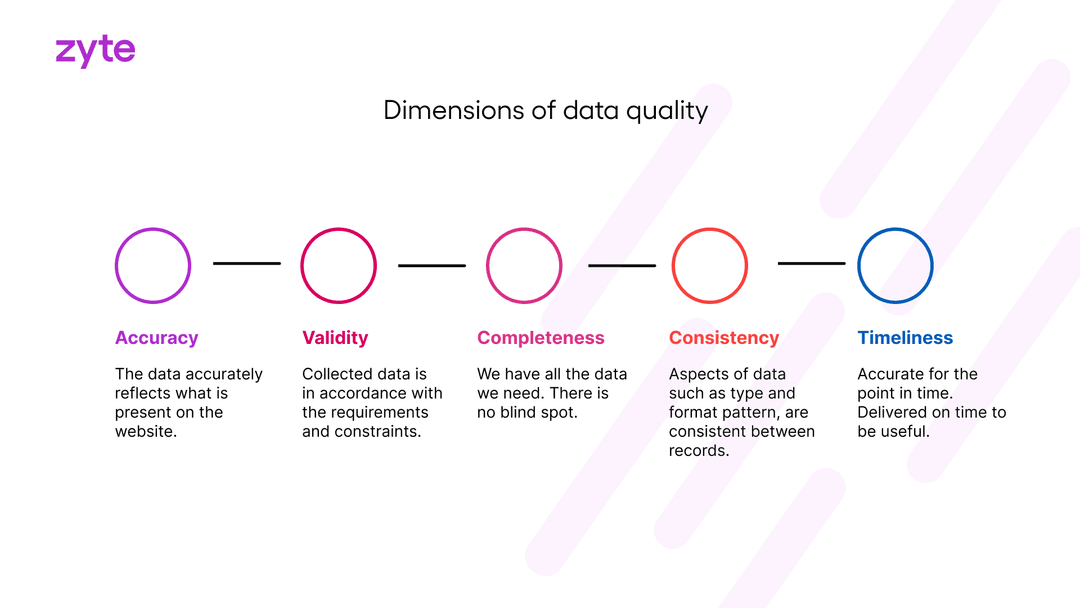
The data quality dimensions you’ll want to check are
accuracy,
validity,
timeliness,
completeness,
uniqueness, and
consistency.
QA has a larger function than just checking for duplicates or errors, it’s about data integrity and ensuring its accuracy for downstream consumption.

4. Scaling and maintaining crawling and extracting solutions
A robust, responsive and reliable web scraping tech stack is key to scaling. Maintenance, reusability, portability, and scalability are challenges team’s face when scaling web scraping operations.
Planning for never-ending maintenance
Web scraping would be easy if websites were static entities. Unfortunately, they’re not and they change often. User interfaces are periodically updated to change layouts, navigation structures or the user experience. Structural changes to the underlying HTML and CSS of a website can cause changes to tags, class names and IDs. For JavaScript-heavy websites there can be changes to scripts or methods. Even updates to the content management system can trigger changes. The biggest maintenance burden for scaling web scraping projects, however, is encountering websites with anti-bot mechanisms deterring web scraping.
These changes break web crawlers and extractors. Your critical data feeds can be broken by changes at any time, impacting downstream systems. It’s a game of whack-a-mole that needs an effective, automated and detailed monitoring and alerting system. You can’t scale unless you’re using automation extensively in your maintenance routines.
Another aspect of maintenance to remember is infrastructure. Custom infrastructure with hosting and compute servers, proxy waterfalls and a lot of custom integration is all going to need maintenance by an expert team.
5. Adding AI to the web scraping tech stack
Web data providers recognize that they can use AI to help scale web scraping. Writing and maintaining manual code are scalability killers. AI is effective for helping teams scale up the creation and maintenance of web crawlers and extractors making it easier to add new sources to solve additional business cases.
Zyte and other vendors have made it easy for companies to benefit from all the AI research without having to make a capital investment. They’ve incorporated machine learning (ML) and large language models (LLM) into their web scraping tech stacks and products.
LLMs have their place in a web scraping stack. They shine when used to gather the insightful but hard to scrape data buried in the unstructured text of a website. It’s best to use a traditional web scraping stack to collect the unstructured data from the website and pass that data to the LLM to extract the additional data points.
Incorporating LLMs into your own web scraping stack raises additional concerns. LLMs are too costly to run as a complete web scraping solution. Additional QA is critical as LLMs can hallucinate. A robust process for testing and correcting errors is needed. Extra scrutiny for legal compliance is needed when incorporating third-party AI systems into your stack to protect your and your client’s data. For example, you want to prevent the third-party AI system from using your data to train their models.
⚡ Tip 4: Use Zyte API’s AI Scraping to take advantage of AI without the capital investment
LLMs are general systems and aren’t built to be a complete web scraping solution and require substantial processing power to run. Using them in most situations isn’t cost-effective when traditional methods are cheaper. Also, LLMs in web scraping must integrate into other solutions for website bans and rendering.
However, generative AI doesn’t have to be a massive expense in your scaling project — outsource it to a third-party vendor.
Zyte API uses a supervised ML model built for extracting structured data and it’s
50x cheaper,
more accurate than larger LLMs,
highly accurate because it uses a human-in-the-loop to correct site-specific issues and retrain the model on specific edge cases.
Zyte API AI Scraping extracts data into legally compliant schemas without the time-intensive task of writing and rewriting xpaths or selectors. We taught our model to find structured data without coding the instructions, making it quick and unbreakable. Want to gather data in the unstructured text too? Zyte API can integrate with your LLM of choice.

6. The In-house vs outsourced question for web scraping at scale
When deciding between in-house, outsourced or hybrid web scraping operations, you need to ask if web data extraction is at the core of your business. The general consensus is that you should build in-house operations if web scraping is a core part of your business. However, it can be more nuanced than that, so let’s take a look at the three options.
In-house
There’s a significant cost impact to scaling web scraping in-house whether you’re starting from scratch or have an existing team. You’ll need initial and ongoing investments in your:
development team,
infrastructure,
quality assurance testing and monitoring,
third-party tooling, and
legal and compliance teams.
But, you get complete control over your web scraping stack and its operations.
Web scraping is a growing, but small specialized discipline in software development. Developers with expertise are hard to recruit and keep. The web keeps changing and so your team needs to keep up with new technologies.
At scale, every web scraping effort needs to purchase and manage third-party tools. This could be proxy services, cloud hosting, storage solutions, development environments and version control, or data cleaning and transformation tools.
It’s imperative that your in-house team have legal oversight by in-house lawyers with a specialization in web scraping to ensure your business is operating legally and ethically. And like developers, these lawyers are specialized and are hard to recruit and keep.
⚡ Tip 5: Use web scraping APIs like Zyte API to reduce your dependency on third-party tooling
Web scraping APIs are a new development in web scraping that condenses a web scraping tech stack into one API. They reduce development time and maintenance on scraping projects. Zyte API is an end-to-end AI-powered web scraping tool for crawling, unblocking and extracting data in minutes. Zyte API automates huge amounts of the work that goes into finding configs that solve opaque bans, monitor success rates, and adapt to any changes. It also contains all the tools you’d need like automated proxy rotation, headless browsers and rendering, and residential proxies. And with Zyte API’s AI scraping ability, it enables developers to build and launch spiders, unblock websites and extract data from a single UI three times faster than legacy scraping vendors and proxy APIs.
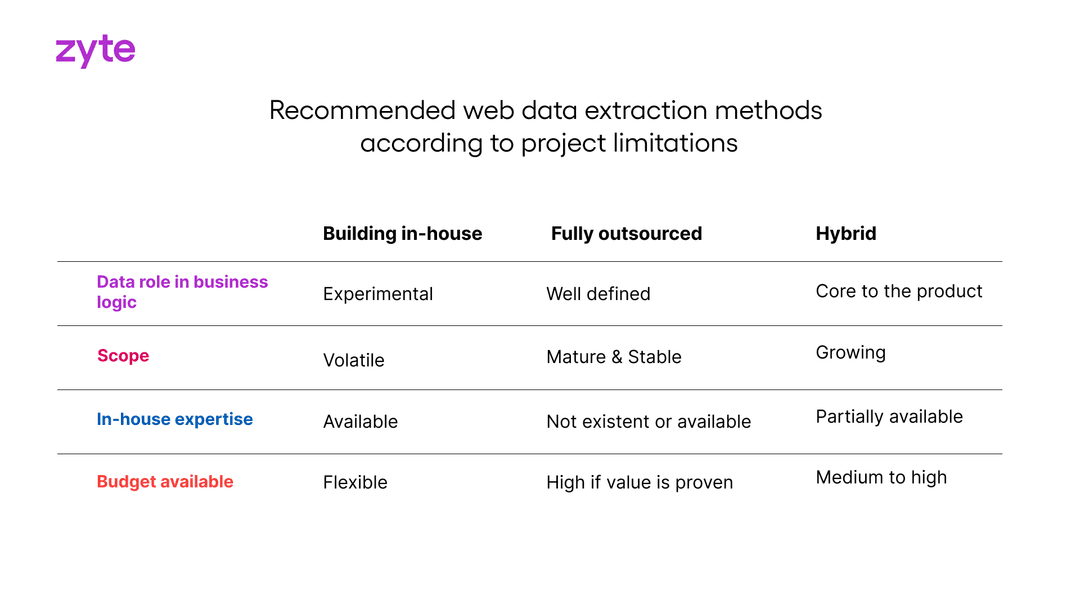
Fully outsourced
If web data extraction isn’t at the core of your business, you’ll need to partner with experts to handle all extraction aspects of a business case. With a strong partner, there’s no burden of carrying the scaling costs and administration of an in-house team. You should still have your own legal representation that understands the law. Remember the third-party’s lawyer isn’t your lawyer.
The fully outsourced option is a good alternative to building an in-house team from scratch, so the opportunity costs related to increased resource investment, operational costs and compliancecan be managed more effectively. You’ll get more predictable pricing with a third-party making your cost estimates more reliable.
Hybrid
You have existing teams and a web scraping tech stack in-house, but can outsource some of the infrastructure or data collection to a 3rd party. Handing off some of the heavy lifting to a dedicated and specialized vendor team can extend your capacity and bridge gaps in data collection.
Hybrid is a good alternative to building an existing in-house team. The opportunity costs related to increased resource investment, operational costs and legal/compliance can be managed more effectively. It also allows you to ramp up the web scraping project faster as the third-party will be ready to begin executing the project as soon as the paperwork is signed.
⚡ Tip 6: Use Zyte Data professional services to compliment your existing team or handle all web scraping efforts
Do you just want the data and not the hassle of managing web scraping in-house? Zyte Data is an expert web data extraction team in your pocket. Our white glove service extracts any web data your business needs, regardless of project size and complexity. This includes a dedicated team and round-the-clock support.
7. Questions to ask when scaling web scraping
Here are some questions to ask your team and partners that can help you with your web scraping scaling journey.
Questions to ask the stakeholders
What business problem are we trying to solve with web data?
How does this align with our key business objectives?
Are you aware of the potential challenges and risks associated with web scraping at scale?
Will this effort consider initial capital investment and the required ongoing funding?
What’s the budget?
What is the timeline of this effort?
What is the priority of this effort compared to other initiatives?
Are we currently operating in a legal and ethical manner?
How well does our legal team understand the complexities of web scraping?
Do we have resources who are experienced with managing large web scraping operations?
What are your expectations for return on investment for this effort?
Where do you see web scraping at scale in the business evolving in the next 5 years?
Questions to ask your QA and development teams
What tooling is part of our web scraping tech stack?
How scalable is our tooling? If it’s not scalable, what would we need to do to change that?
Do we have resources who are experienced with managing and maintaining large web scraping operations?
Do we have enough resources to scale?
What challenges have we encountered so far and how did we overcome them?
Do we have the infrastructure required to scale? If not, what is needed?
How are we currently managing website bans and how would these strategies change at scale?
How is the team currently managing web scraping projects?
What’s our current end-to-end workflow from development, testing, deployment, and maintenance?
How will scaling affect ongoing projects and priorities?
Do you trust data from targeted websites?
How do you find reliable and quality web data?
What happens when you find conflicting data gathered from multiple sources?
Questions to ask a third-party
What industries have you worked with?
What data have you been asked to extract?
What is your web scraping tech stack?
How do you handle website changes and anti-bot technology?
How do you ensure the quality of the data at large volumes?
How do you ensure legal compliance within your scraping projects?
What ethical guidelines do you follow?
Are you certified by the EWDCI?
What’s your project management approach?
How do you communicate with clients?
What is your pricing structure and additional costs?
What is your security strategy to protect the data collected?
How do you handle security incidents?
What are your support strategies and SLAs?
Scaling a web scraping operation has a lot of moving parts. You can talk to our web scraping specialists to help you build a stronger business case to get the best results from your scaling efforts. And when scaling in-house, your development team should sign up for a free trial to Zyte API. They can get hands-on experience with an end-to-end tool for crawling, unblocking and extracting data that can help your business scale.
More learn articles
Keep learning
 Use case
Use caseWhat is a residential proxy?
Learn what residential proxies are, how they compare to datacenter proxies, and why modern web scraping needs more than IP diversity.
10 min read · May 29, 2026
 Use case
Use caseHow much do rotating proxies cost?
Learn how much rotating proxies cost, what affects pricing, and why total web scraping costs often go beyond proxy subscriptions.
10 min read · May 29, 2026
Use caseHow do rotating proxies work?
Learn how rotating proxies work, when to use them for web scraping, and why IP rotation alone is not enough for reliable data access.
10 min read · May 29, 2026




_HFpro5d6k3.png&w=256&q=75)
_E4PyVpfAxa.png&w=256&q=75)


-(1).png&w=1920&q=75)
-(1)_VZGHqxCgXV.png&w=1920&q=75)
